Tradicionalmente, para realizar acceso a datos desde un lenguaje orientado a objetos (POO) como pueden ser .NET o Java, era necesario mezclar código y conceptos muy diferentes. Estas diferencias entre conceptos, tipos de datos, y modos de trabajar pueden causar muchos problemas de lo que se dio en llamar "desfase de impedancia". El concepto se refiere a la dificultad para hacer fluir la información entre la base de datos y las diferentes capas del programa en función de la diferencia existente entre cada una de estas partes. Este desfase de impedancia hace que pueda llegar a ser muy complicado trabajar contra una base de datos desde un lenguaje POO si queremos sacar partido a los conceptos habituales que usamos en éstos, y huir de bibliotecas de funciones que nos fuerzan a trabajar con los conceptos de la base de datos. En este artículo vamos a ver cuáles son estos problemas y qué es lo que nos permite disminuir esta impedancia (o sea, un ORM), sus ventajas e inconvenientes y cuáles hay para las diferentes plataformas.
Tradicionalmente, para realizar acceso a datos desde un lenguaje orientado a objetos (POO) como pueden ser .NET o Java, era necesario mezclar código y conceptos muy diferentes.
Por un lado teníamos la aplicación en sí, escrita en alguno de estos lenguajes como C# o Java. Dentro de éste programa hacíamos uso de ciertos objetos especializados en conectarse con bases de datos y lanzar consultas contra ellas. Estos objetos de tipo Connection, Query y similares, eran en realidad conceptos de la base de datos llevados a un programa orientado a objetos que no tenía nada que ver con ellos. Finalmente, para lanzar consultas (tanto de obtención de datos como de modificación o de gestión) se introducían instrucciones en lenguaje SQL, en forma de cadenas de texto, a través de estos objetos.
Además estaba el problema de los tipos de datos. Generalmente el modo de representarlos y sus nombres pueden variar entre la plataforma de desarrollo y la base de datos. Por ejemplo, en .NET un tipo de datos que almacena texto es simplemente un string. En SQL Server para lo mismo podemos utilizar cadenas de longitud fija o variable, de tipo Unicode o ANSI, etc... Y lo mismo con los otros tipos de datos. Algunos ni siquiera tienen por qué existir en el lenguaje de programación. Y tampoco debemos olvidarnos de los valores nulos en la base de datos, que pueden causar todo tipo de problemas según el soporte que tengan en el lenguaje de programación con el que nos conectamos a la base de datos.
Otros posibles problemas y diferencias surgen del modo de pensar que tenemos en un lenguaje orientado a objetos y una base de datos. En POO, por ejemplo, para representar una factura y sus líneas de factura podrías definir un objeto Factura con una propiedad Lineas, y si quieres consultar las líneas de una factura solo debes escribir factura.Lineas y listo, sin pensar en cómo se relacionan o de dónde sale esa información. En una base de datos, sin embargo, esto se modela con dos tablas diferentes, una para las facturas y otra para las líneas, además de ciertos índices y claves externas entre ellas que relacionan la información. Si además se diese el caso de que una misma línea de factura pudiese pertenecer a más de una factura, necesitas una tercera tabla intermedia que se relaciona con las dos anteriores y que hace posible localizar la información. Como vemos formas completamente diferentes de pensar sobre lo mismo.
La complejidad no termina aquí ya que las bases de datos tienen procedimientos almacenados (que son como pequeños programas especializados que se ejecutan dentro de la base de datos), transacciones, y otros conceptos que desde el punto de vista de un lenguaje POO son completamente extraterrestres y ajenos.
Estas diferencias entre conceptos, tipos de datos, y modos de trabajar pueden causar muchos problemas de lo que se dio en llamar "desfase de impedancia" o "impedance mismatch" en inglés, en una clara analogía los circuitos eléctricos y al flujo eléctrico (en este caso aplicado a flujo de información). El concepto se refiere a la dificultad para hacer fluir la información entre la base de datos y las diferentes capas del programa en función de la diferencia existente entre cada una de estas partes.
Este desfase de impedancia hace que pueda llegar a ser muy complicado trabajar contra una base de datos desde un lenguaje POO si queremos sacar partido a los conceptos habituales que usamos en éstos, y huir de bibliotecas de funciones que nos fuerzan a trabajar con los conceptos de la base de datos.
"Mapeadores" al rescate
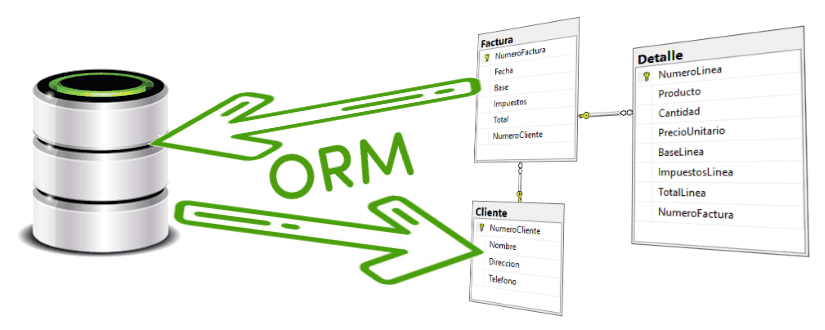
Como acabamos de ver, lo ideal en una aplicación escrita en un lenguaje orientado a objetos sería definir una serie de clases, propiedades de éstas que hagan referencia a las otras, y trabajar de modo natural con ellas.
¿Qué quieres una factura? Simplemente instancias un objeto Factura pasándole su número de factura al constructor. ¿Necesitas sus líneas de detalle? LLamas a la propiedad Lineas del objeto. ¿Quieres ver los datos de un producto que está en una de esas líneas? Solo lee la propiedad correspondiente y tendrás la información a tu alcance. Nada de consultas, nada de relaciones, de claves foráneas...
En definitiva nada de conceptos "extraños" de bases de datos en tu código orientado a objetos. En la práctica para ti la base de datos es como si no existiera.
Eso precisamente es lo que intenta conseguir el software llamado ORM, del inglés Object-Relational Mapper o "Mapeador" de relacional a objetos (y viceversa). Un ORM es una biblioteca especializada en acceso a datos que genera por ti todo lo necesario para conseguir esa abstracción de la que hemos hablado.
Gracias a un ORM ya no necesitas utilizar SQL nunca más, ni pensar en tablas ni en claves foráneas. Sigues pensando en objetos como hasta ahora, y te olvidas de lo que hay que hacer "por debajo" para obtenerlos.
El ORM puede generar clases a partir de las tablas de una base de datos y sus relaciones, o hacer justo lo contrario: partiendo de una jerarquía de clases crear de manera transparente las entidades necesarias en una base de datos, ocupándose de todo (ni tendrás que tocar el gestor de bases de datos para nada).
¿Qué ORMs tenemos disponibles?
-
En el mundo Java el ORM más conocido y utilizado es Hibernate que pertenece a Red Hat aunque es gratuito y Open Source. Hay muchos otros como Jooq, ActiveJDBC que trata de emular los Active Records de Ruby On Rails, o QueryDSL, pero en realidad ninguno llega ni por asomo al nivel de uso de Hibernate. Si necesitas un ORM en Java debes aprender Hibernate, y luego ya si quieres te metes con otro, pero este es indispensable.
-
En la plataforma .NET tenemos varios conocidos, pero el más popular y utilizado es Entity Framework o EF, que es el creado por la propia Microsoft y que viene incluido en la plataforma .NET (tanto en la "tradicional" como en .NET Core). También existe un "port" de Hibernate para .NET llamado NHibernate y que a mucha gente le gusta más que EF. Hay otros como Dapper que está creado por la gente de Stack Exchange y es mucho más sencillo que los anteriores, lo cual es considerado una gran virtud por mucha gente (entre los que me incluyo), y también es muy utilizado. Y es muy conocido Subsonic, que lleva casi diez años en activo pero que puede llegar a ser bastante complicado (a mí personalmente no me gusta nada).
En PHP tienes Doctrine, tal vez el más conocido y recomendado (utilizado por el framework Symfony), pero también se usan bastante Propel, RedbeanPHP y uno muy popular pero ya en desuso es Xyster (pero te lo encontrarás aún bastante por ahí).
En Python el híper-conocido framework Django (así sinónimo de desarrollo web con este lenguaje) incluye su propio ORM, pero también tenemos SQLAlchemy por el que muchos beben los vientos y lo califican como el mejor ORM jamás hecho (no tengo experiencia con él como para saberlo). También están Peewee o Pony ORM entre otros.
Prácticamente todas las plataformas tienen el suyo, así que búscalos para la tuya y mira cuál es el más popular y el que más comunidad reúne.
Ventajas e inconvenientes de un ORM
Los ORM ofrecen enormes ventajas, como ya hemos visto, al reducir esa "impedancia" que impide el buen flujo de información entre los dos paradigmas POO-Relacional. Pero además:
- No tienes que escribir código SQL, algo que muchos programadores no dominan y que es bastante complejo y propenso a errores. Ya lo hacen por nosotros los ORM.
- Te dejan sacar partido a las bondades de la programación orientada a objetos, incluyendo por supuesto la herencia, lo cual da mucho juego para hacer cosas.
- Nos permiten aumentar la reutilización del código y mejorar el mantenimiento del mismo, ya que tenemos un único modelo en un único lugar, que podemos reutilizar en toda la aplicación, y sin mezclar consultas con código o mantener sincronizados los cambios de la base de datos con el modelo y viceversa.
- Mayor seguridad, ya que se ocupan automáticamente de higienizar los datos que llegan, evitando posibles ataques de inyección SQL y similares.
- Hacen muchas cosas por nosotros: desde el acceso a los datos (lo obvio), hasta la conversión de tipos o la internacionalización del modelo de datos.
Pero no todo va a ser alegría. También tienen sus inconvenientes:
- Para empezar pueden llegar a ser muy complejos. Por ejemplo, NHibernate tiene ya más de medio millón de líneas de código ahora mismo, y muchas clases y detalles que hay que saber. Eso hace que su aprendizaje sea complejo en muchos casos, y hay que invertir tiempo en aprenderlos y practicar con ellos hasta tener seguridad en su manejo diario.
- No son ligeros por regla general: añaden una capa de complejidad a la aplicación que puede hacer que empeore su rendimiento, especialmente si no los dominas a fondo. En la mayor parte de las aplicaciones probablemente no te importe, pero en ocasiones su impacto en el rendimiento es algo a tener muy en cuenta. En general una consulta SQL directa será más eficiente siempre.
- La configuración inicial que requieren se puede complicar dependiendo de la cantidad de entidades que se manejen y su complejidad, del gestor de datos subyacente, etc...
- El hecho de que te aísle de la base de datos y no tengas casi ni que pensar en ella es un arma de doble filo. Si no sabes bien lo que estás haciendo y las implicaciones que tiene en el modelo relacional puedes construir modelos que generen consultas monstruosas y muy poco óptimas contra la base de datos, agravando el problema del rendimiento y la eficiencia.
En definitiva, los ORM son una herramienta que puede llegar a ser maravillosa, pero que en aplicaciones pequeñas pueden ser como "matar moscas a cañonazos". En aplicaciones más grandes donde el mantenimiento y la homogeneidad sean importantes, son indispensables. Eso sí, no te eximen de aprender bien el lenguaje SQL o las maneras más tradicionales de realizar acceso a datos, ya que conocerlas puede marcar la diferencia cuando surjan problemas o haya que determinar por qué se produce una merma de rendimiento, etc...