Sin duda la tendencia tecnológica más puntera de los últimos años es todo lo relacionado con la inteligencia artificial y el análisis de datos. El problema viene cuando los términos relacionados con el campo se convierten en palabras vacías de marketing que en muchos casos son directamente mentira. Es muy habitual hablar de que tal o cual producto usa la inteligencia artificial para lograr algo y, en ocasiones, son algoritmos convencionales tomando decisiones predecibles. En este artículo te explicamos de manera concisa y clara qué significan cada uno de los términos más comunes relacionados con la ciencia de datos y la inteligencia artificial.

El mundo de la tecnología, como cualquier otro, no es inmune a las modas. Y estas modas hacen que ciertas palabras y conceptos se utilicen de manera arbitraria, como simples palabras huecas de marketing, que al final acaban perdiendo la sustancia y la validez de tanto usarlas mal. Así que cada vez que hay una tecnología en ascenso se generan ciertas buzzwords que todo el mundo utiliza y que no puedes dejar de escuchar y leer por todas partes.
Sin duda la tendencia tecnológica más puntera de los últimos años es todo lo relacionado con la inteligencia artificial y el análisis de datos. Y es que de manera relativamente reciente se han dado grandes avances en este campo, que unidos a la disponibilidad de enormes cantidades de datos y cada vez mayor potencia de cómputo están dando lugar a todo tipo de aplicaciones prácticas muy interesantes.
El problema viene cuando los términos relacionados con el campo se convierten en palabras vacías de marketing que en muchos casos son directamente mentira. Es muy habitual hablar de que tal o cual producto usa la inteligencia artificial para lograr algo y, en ocasiones, son algoritmos convencionales tomando decisiones predecibles. Como dice el famoso Tweet de I Am Devloper:
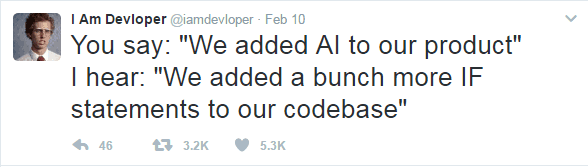
O como la siempre estupenda tira cómica de CommitStrip en la que se ve a un comercial presentando a un maravilloso robot que usa IA pero que, al romperlo, dentro solo tiene miles de condicionales:

Pero incluso cuando se usan con toda la buena intención, a veces resulta complicado discernir qué es cada cosa cuando se habla de tantos términos relacionados que no todo el mundo conoce bien.
En este artículo trataré de explicarte de manera concisa y clara qué significan cada uno de los términos más comunes relacionados con la ciencia de datos y la inteligencia artificial.
¡Allá vamos!
¿Qué es la Inteligencia Artificial?
La inteligencia artificial (IA o AI) nació como ciencia hace ya muchos años, cuando las posibilidades de las computadoras eran realmente limitadas, y se refiere a lograr que las máquinas simulen las funciones del cerebro humano.
La IA se clasifica en dos categorías según sus capacidades:
- IA general (o fuerte): que intenta lograr máquinas/software capaces de tener inteligencia en el sentido más amplio de la palabra, en actividades que implican entender, pensar y razonar en cuestiones de carácter general, en cosas que cualquier ser humano puede hacer.
- IA estrecha (o débil): que se centra en dotar de inteligencia a una máquina/software dentro de un ámbito muy concreto y cerrado o para una tarea muy específica.
Así, por ejemplo, una IA fuerte sería capaz de aprender por sí misma y sin intervención externa a jugar a cualquier juego de mesa que le "pongamos delante", mientras que una IA débil aprendería a jugar a un juego concreto como el ajedrez o el Go. Es más, una hipotética IA fuerte entendería qué es el juego, cuál es el objetivo y cómo se juega, mientras que la IA débil, aunque juegue mejor que nadie al Go (un juego tremendamente complicado) no tendrá ni idea realmente de qué está haciendo.
Una de las cuestiones cruciales a la hora de distinguir un sistema de inteligencia artificial de un mero software tradicional (por complejo que sea, lo cual nos lleva a los chistes de arriba) es que la IA se "programa" sola. Es decir, no consiste en una serie de secuencias lógicas predecibles, sino que tienen la capacidad de generar por su cuenta razonamientos lógicos, aprendizaje y autocorrección.
El campo ha avanzado mucho en estos años y tenemos IAs débiles capaces de hacer cosas increíbles. Las IAs fuertes siguen siendo un sueño de investigadores, y la base del guion de muchas novelas y películas de ciencia-ficción.
¿Qué es Machine Learning?
El Machine Learning (ML) o aprendizaje automático se considera un subconjunto de la inteligencia artificial. Se trata de una de las maneras de las que disponemos para lograr que las máquinas aprendan y "piensen" como los humanos. Como su propio nombre indica, las técnicas de ML se utilizan cuando queremos que las máquinas aprendan de la información que les proporcionamos. Es algo análogo a cómo aprenden los bebés humanos: a base observación, prueba y error. Se les proporcionan datos suficientes para que puedan aprender una tarea determinada y limitada (recuerda: IA débil), y luego son capaces de aplicar ese conocimiento a nuevos datos, corrigiéndose y aprendiendo más con el tiempo.
Existen muchas maneras de enseñar a una máquina a "aprender": técnicas de aprendizaje supervisado, no supervisado, semisupervisado y por refuerzo, en función de si se le da la solución correcta al algoritmo mientras aprende, no se le da la solución, se le da a veces o sólo se le puntúa en función de lo bien o mal que lo haga, respectivamente. Y existen multitud de algoritmos que se pueden utilizar para diferentes tipos de problemas: predicción, clasificación, regresión, etc...
Puede que hayas oído hablar de algoritmos como regresión lineal simple o polinómica, máquinas de vectores soporte, árboles de decisión, Random Forest, K vecinos más cercanos.... Estos son solo algunos de los algoritmos comunes utilizados en ML. Pero existen muchos más.
Pero conocer estos algoritmos y para qué sirven (para entrenar al modelo) es solo una de las cosas que se necesitan conocer. Antes es también muy importante aprender a obtener y cargar los datos, hacer análisis exploratorio de los mismos, limpiar la información... De la calidad de los datos depende la calidad del aprendizaje, o como suele decirse en ML: "Basura entra, basura sale".
En la actualidad las bibliotecas de Machine Learning para Python y R han evolucionado mucho, por lo que incluso un desarrollador sin conocimientos de matemáticas o estadística más allá de las del instituto, puede construir, entrenar, probar, desplegar y usar modelos de ML para aplicaciones del mundo real. Aunque es muy importante conocer bien todos los procesos y entender cómo funcionan todos estos algoritmos para tomar buenas decisiones a la hora de seleccionar el más apropiado para cada problema.
¿Qué es Deep Learning?
Dentro de Machine Learning existe una rama denominada Deep Learning (DL) que tiene un enfoque diferente a la hora de crear aprendizaje automático. Sus técnicas se basan en el uso de lo que se llaman redes neuronales artificiales. Lo de "deep" (profundo) se refiere a que las actuales técnicas son capaces de crear redes de muchas capas neuronales de profundidad, consiguiendo resultados impensables hace poco más de una década, ya que se han creado grandes avances desde el año 2010, unidos a las grandes mejoras en capacidad de cálculo.
En los últimos años se ha aplicado Deep Learning con un éxito apabullante a actividades relacionadas con el reconocimiento de voz, procesado del lenguaje, visión artificial, traducción automática, filtrado de contenidos, análisis de imágenes médicas, bioinformática, diseño de fármacos... obteniendo resultados iguales o mejores que los de humanos expertos en el campo de aplicación. Aunque no hace falta irse a cosas tan especializadas para verla en acción: desde las recomendaciones de Netflix a tus interacciones con tu asistente de voz (Alexa, Siri o el asistente de Google) pasando por las aplicaciones del móvil que te cambian la cara... todas ellas usan Deep Learning para funcionar.
En general, se suele decir (cójase con pinzas) que si la información de la que dispones es relativamente poca y el número de variables que entran en juego relativamente pequeño, las técnicas generales de ML son las más indicadas para resolver el problema. Pero si tienes enormes cantidades de datos para entrenar a la red y hay miles de variables involucradas, entonces el Deep Learning es el camino a seguir. Ahora bien, debes tener en cuenta que el DL es más difícil de implementar, lleva más tiempo entrenar a los modelos y necesita mucha más potencia de cálculo (normalmente "tiran" de GPUs, procesadores gráficos optimizados para esta tarea), pero es que los problemas normalmente son más complejos también. Para que te hagas una idea, el mítico GPT-3 utiliza 175.000 millones de parámetros entrenables.
Pero no todo son modelos gigantes. Existen redes que pueden resolver problemas avanzados (detección de objetos, atributos faciales, clasificación precisa) ejecutándose en dispositivos móviles y sistemas empotrados, como las MobileNet que pueden tener menos de 1 millón de parámetros.
¿Qué es el Big Data?
El concepto de Big data es mucho más sencillo de entender. Dicho en palabras sencillas, esta disciplina agrupa las técnicas necesarias para capturar, almacenar, homogeneizar, transferir, consultar, visualizar y analizar datos a gran escala y de manera sistemática.
Piensa por ejemplo en los datos de miles de sensores de la red eléctrica de un país que envían datos cada segundo para ser analizados, o la información generada por una red social como Facebook o Twitter con centenares (o miles) de millones de usuarios. Estamos hablando de volúmenes enormes y continuos que no son apropiados para usar con sistemas tradicionales de procesamiento de datos, como bases de datos SQL o paquetes de estadística estilo SPSS.
El Big Data se caracteriza tradicionalmente por las 3 V:
- Volumen elevado de información. Por ejemplo, Facebook tiene 2 000 millones de usuarios y Twitter cerca de 400 millones, que están constantemente dotando de información a esas redes sociales en volúmenes elevadísimos, y es necesario almacenarla y gestionarla.
- Velocidad: siguiendo con el ejemplo de las redes sociales, cada día Facebook recoge del orden de 1000 millones de fotos y Twitter gestiona más de 500 millones de tweets, eso sin contar likes, y muchos otros datos. El Big Data lidia con esa velocidad de recepción de datos y su procesamiento de modo que pueda fluir y ser procesada adecuadamente y sin cuellos de botella.
- Variedad: se pueden recibir infinidad de datos de diferente naturaleza, algunos estructurados (como la lectura de un sensor, o un like) y otros desestructurados (como una imagen, el contenido de un tweet o una grabación de voz). Las técnicas de Big Data deben lidiar con todos ellos, gestionarlos, clasificarlos y homogeneizarlos.
Otro de los grandes retos asociados a la recogida de este tipo de información masiva tiene que ver con la privacidad y la seguridad de dicha información, así como la calidad de los datos para evitar sesgos de todo tipo.
Como ves, las técnicas y conocimientos necesarios para hacer Big Data no tienen nada que ver con las que se requieren para AI, ML o DL, aunque muchas veces se use el término muy a la ligera.
Estos datos pueden nutrir a los algoritmos utilizados en las técnicas anteriores, es decir, pueden ser la fuente de información de la que se nutran modelos especializados de Machine Learning o de Deep Learning. Pero también pueden ser utilizados de otras maneras, lo cual nos lleva a...
¿Qué es la ciencia de datos?
Al hablar de ciencia de datos nos referimos en muchos casos a la extracción de información relevante de los conjuntos de datos, denominado también KDD (Knowledge Discovery in Databases, descubrimiento de conocimiento en bases de datos). Utiliza diversas técnicas de muchos campos: matemáticas, programación, modelado estadístico, visualización de datos, reconocimiento y aprendizaje de patrones, modelado de incertidumbre, almacenamiento de datos y computación en la nube.
Ciencia de datos se puede referir también, de forma más amplia a los métodos, procesos y sistemas que involucran tratamiento de datos para esa extracción de conocimiento. Puede englobar desde técnicas estadísticas y de análisis de datos, hasta los modelos inteligentes que aprenden "por sí mismos" (no supervisados), lo que tocaría parte de Machine Learning también. De hecho, este término se puede confundir con minería de datos (más de moda hace unos años) o con el propio Machine Learning.
Los expertos en ciencia de datos (llamados muchas veces científicos de datos) se enfocan en la resolución de problemas que involucran datos complejos, y buscan patrones en la información, correlaciones relevantes y, en definitiva, obtener conocimientos a partir de los datos. Suelen ser expertos en matemáticas, estadística y programación (aunque no tienen que ser expertos en las tres cosas).
Al contrario que los expertos en Inteligencia Artificial (o Machine Learning o Deep Learning), que buscan la manera de generalizar la solución a problemas mediante el aprendizaje automático, los científicos de datos generan conocimientos particulares y específicos a partir de los datos de los que parten. Lo cual es una diferencia sustancial del enfoque, y de los conocimientos y de las técnicas necesarias para cada especialización.
En resumen
Como has visto en este repaso, todos estos términos tan comunes en la actualidad y muchas veces usados a la ligera, están relacionados entre sí, a veces de manera íntima, pero no son lo mismo y es necesario distinguirlos y utilizarlos con precisión.
El siguiente diagrama, que he hecho yo mismo a mano alzada a partir de las sugerencias de David Charte (que también ha revisado el artículo como experto en la materia), creo que es un buen resumen visual de todo lo que he explicado en el texto del artículo y ayuda a situar cada especialidad en relación a las demás:
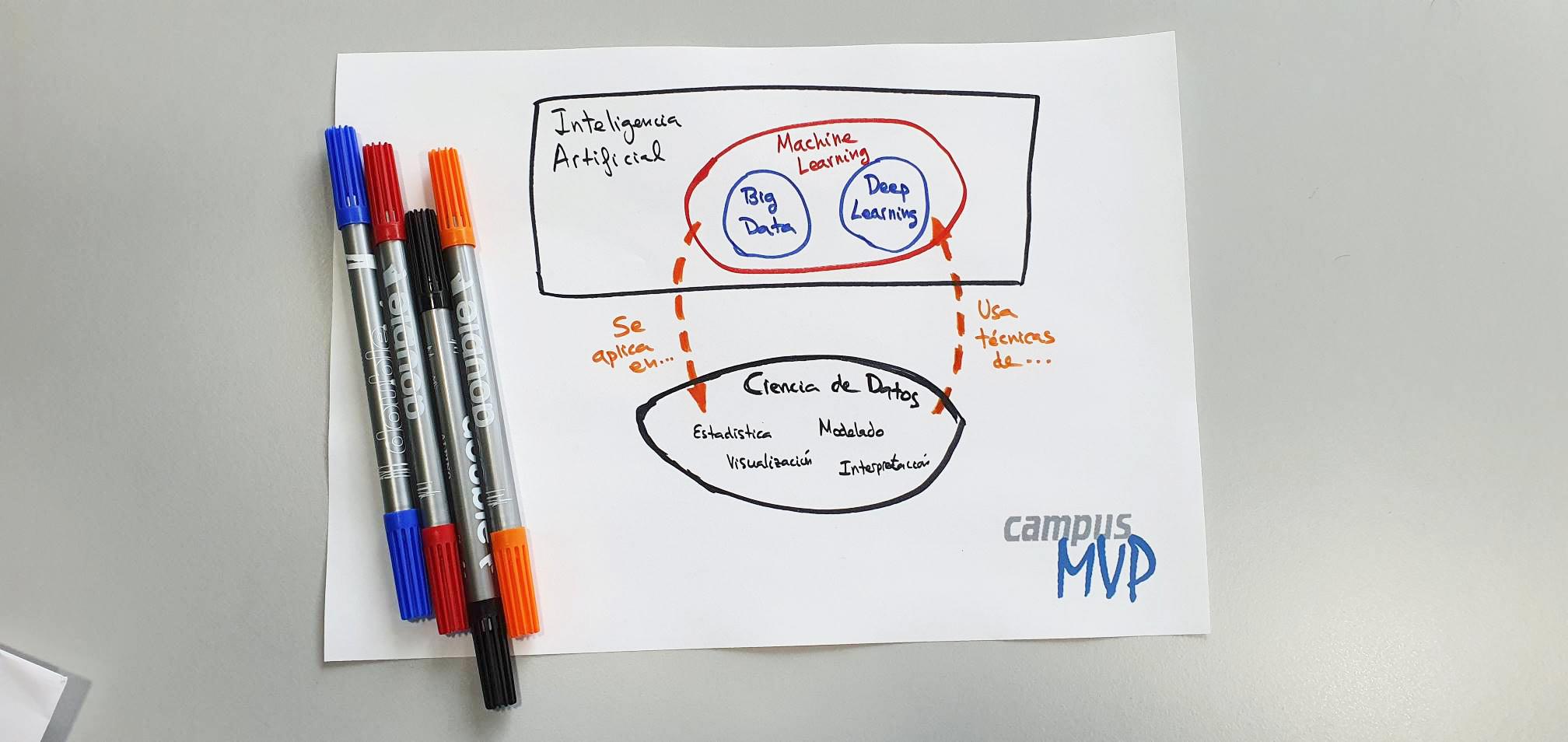
Espero que estas explicaciones te hayan ayudado a aclarar conceptos y, si tienes interés en dedicarte a este mundo, a decidirte por una u otra en función de tus intereses y capacidades.