En este artículo te explicamos las diferentes opciones que existen para acceder a los datos de una base de datos relacional con Java. Verás las ventajas y desventajas de cada una, y cómo elegir la que mejor se adapte a tus necesidades. Aprenderás sobre JDBC, JPA, Hibernate y Spring Data JPA, y cómo se relacionan entre sí. También te daremos algunos consejos y recomendaciones para usar estas tecnologías de forma eficiente y segura.

Una de las tareas más comunes y necesarias que realiza un desarrollador es el acceso a datos. Los datos son la materia prima con la que trabajamos, y poder almacenarlos, consultarlos, modificarlos y eliminarlos de forma eficiente y segura es fundamental para el éxito de cualquier proyecto.
Para acceder a los datos almacenados en una base de datos relacional, existen diferentes opciones que se pueden clasificar en dos grandes categorías: el acceso a bajo nivel y el acceso mediante un ORM (Object-Relational Mapping, puedes conocer más sobre este concepto en este artículo: "¿Qué es un ORM?").
El acceso a bajo nivel consiste en utilizar directamente el lenguaje SQL (Structured Query Language) para realizar consultas y operaciones sobre la base de datos. Para ello, se necesita una biblioteca que permita establecer una conexión con la base de datos y enviar y recibir los datos. En Java, esta librería se llama JDBC (Java Database Connectivity) y es la forma más básica y estándar de acceder a los datos.
El acceso mediante un ORM consiste en utilizar una capa de abstracción que mapea las tablas y columnas de la base de datos con las clases y atributos de Java. De esta forma, se puede trabajar con los datos como si fueran objetos de Java, sin necesidad de escribir código SQL. En Java, existen varias librerías que implementan el concepto de ORM, y que vamos a ver a continuación.
En este artículo veremos todas estas opciones populares para acceder a los datos con Java y las compararemos para ver cuál te conviene más.
JDBC (Java Database Connectivity)
Es la API "base" de Java para el acceso a los datos de bases de datos relacionales. Te permite ejecutar consultas SQL directamente en la base de datos y manejar los resultados en tu aplicación Java. JDBC te da un control total sobre las consultas SQL y cómo se manejan los datos, pero también significa que debes escribir más código y manejar más detalles de bajo nivel.
Básicamente te proporciona la forma de hacer 3 cosas:
- Conectarte a una base de datos
- Enviarle consultas SQL tanto de consulta como de manipulación de datos
- Recibir los resultados de las consultas
Es una API muy "pegada" a la base de datos, ya que no tiene intermediarios entre tu código y ésta, más allá del "driver" que permite la comunicación entre ambos:
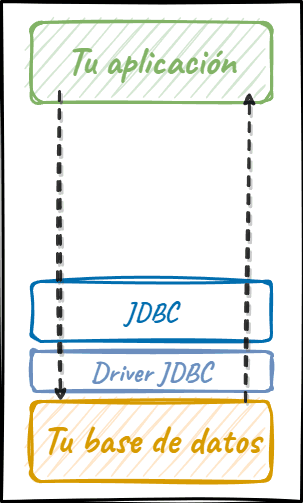
JPA (Jakarta Persistence)
Cuando queremos trabajar con objetos en lugar de con consultas SQL lo que necesitamos es un ORM. Es decir, necesitamos alguna biblioteca adicional que genere las consultas, las lance y mapee los resultados de estas a los objetos correspondientes.
Para ayudarnos con esto, Java dispone de una especificación que define cómo se deben mapear los objetos de Java a las tablas de una base de datos relacional. A esta especificación se le llama JPA.
Inicialmente JPA significaba Java Persistence API, pero en 2019 Oracle hizo que la tecnología Java EE (que incluía esta especificación) fuese de código abierto y la donó a la fundación Eclipse. Desde entonces otras organizaciones (EclipseLink, Hibernate y DataNucleus) se encargan de su mantenimiento, y le cambiaron el nombre ya que "Java" es una marca registrada de Oracle y no la podían utilizar. Jakarta, la capital de Indonesia que es donde está la isla de Java, fue el elegido por la comunidad como nuevo nombre para Java EE. Esto forzó entre otras cosas el cambio de nombre de los paquetes correspondientes que pasaron de estar de javax.persistence a jakarta.persistence.
Es decir, JPA no es una tecnología que podamos utilizar directamente, sino que se encarga de definir una serie de conceptos que una biblioteca concreta debe implementar. Dicho de manera muy simple y para que se entienda mejor, JPA es como una interfaz en Java, que define con qué miembros debe contar una implementación (una clase en el símil) como es Hibernate.
Por eso, JPA no es realmente una tecnología de acceso a datos y no es una opción a la que podamos acudir de manera directa para acceder a nuestras bases de datos. Pero eso sí, como define la manera de actuar de otras tecnologías, sí que se trata de una capa más de complejidad que tenemos entre nuestra aplicación y los datos.
Hibernate
Hibernate es una implementación concreta de la especificación JPA. La más conocida y utilizada seguramente.
Además de las funcionalidades que define JPA, Hibernate ofrece características adicionales como las cachés de nivel 1 y 2, la carga perezosa ("lazy", solo carga los datos cuando se necesitan, en lugar de todos de golpe), y la optimización de consultas entre otras cosas.
A priori te simplifica el trabajo de acceso a datos porque te permite utilizar objetos directamente y te evita las consultas SQL y el mapeo de estas. Sin embargo, Hibernate puede ser más difícil de aprender y usar correctamente que JDBC, especialmente si no entiendes bien cómo funciona la persistencia de objetos.
Así que con Hibernate se añade una capa de complejidad más, y la situación es la siguiente:
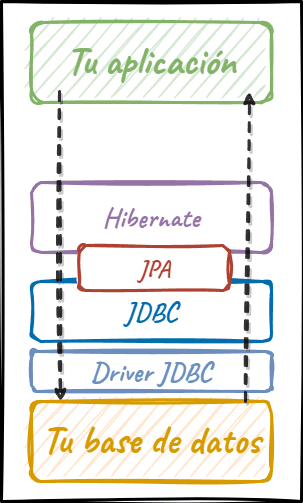
Con Hibernate tenemos al propio Hibernate y a JPA entre nuestra aplicación y los datos, además de la capa de bajo nivel y el driver.
OJO: en realidad JPA no es una capa de código como las demás que se ven en la figura, sino que es una especificación que implementa, en este caso, Hibernate (además de sus propias clases adicionales). Por ello, en realidad debería dejarla fuera de la ilustración pues es neutra en lo que respecta al código. Sin embargo, he decido ponerla porque ilustra bien la relación que existe con las demás capas, que sí son de código.
Spring Data JPA
Muchos desarrolladores de Java utilizan el framework Spring, y más en particular Spring Boot, para desarrollar sus aplicaciones.
Spring Framework es un marco de desarrollo de aplicaciones Java que facilita la creación de aplicaciones empresariales robustas y modulares al proporcionar un conjunto integral de funcionalidades, como inversión de control, contenedor de beans o gestión de transacciones. Por otro lado, Spring Boot es una extensión de ese framework que simplifica aún más el desarrollo al ofrecer una configuración predeterminada "sensata" para aplicaciones basadas en Spring, permitiendo la creación rápida de aplicaciones autocontenidas con empaquetado y despliegue sencillos. Utilizar Spring y Spring Boot proporciona ventajas como la flexibilidad, la modularidad, la escalabilidad y una amplia gama de características integradas que aceleran el desarrollo de aplicaciones empresariales.
Spring Data JPA es una parte de Spring Data. Proporciona un conjunto de abstracciones y convenciones para simplificar la implementación de repositorios de datos. Spring Data JPA genera automáticamente implementaciones para los métodos de consulta comunes en tus interfaces de repositorio, lo que puede ahorrar mucho tiempo en comparación con la implementación manual de estos métodos. Sin embargo, Spring Data JPA requiere que uses por debajo alguna implementación de JPA (por defecto utiliza Hibernate) para realizar las operaciones de base de datos.
Así que con Spring Data JPA, la cosa queda así:
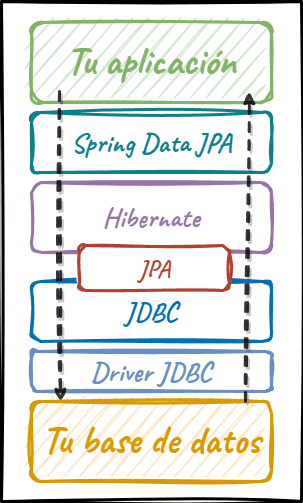
Es decir, añade otra capa de complejidad más entre tu aplicación y la base de datos, aunque te permita escribir código más sencillo de manera más productiva.
¿Qué tecnología de acceso a datos con Java debo utilizar?
Como ves, cada nueva capa añade más abstracción entre tu código y los datos de tu base de datos relacional. Al mismo tiempo, cada capa pretende facilitarte la vida más a la hora de trabajar con los objetos de tu aplicación, pero hace que sea más complicado aprender y utilizar la tecnología.
Es decir, al final se trata de encontrar un equilibrio entre rendimiento y facilidad de trabajo.
Si comparamos la solución nativa de más bajo nivel, JDBC, con el uso de un ORM como Hibernate, las ventajas de JDBC sobre cualquier proveedor JPA son:
- Control total sobre las consultas SQL: con JDBC puedes escribir tus propias consultas SQL y tener un control total sobre ellas. Esto puede ser útil si necesitas realizar operaciones específicas que no son posibles o son más difíciles de realizar con las abstracciones proporcionadas por JPA o Hibernate. Además, si dominas SQL a veces te resultará más natural hacerlo de este modo.
- Menos abstracción: JDBC es una API de bajo nivel que se comunica directamente con la base de datos. Esto significa que no hay mucha abstracción entre tu código Java y las consultas SQL que se ejecutan en la base de datos. Esto puede hacer que JDBC sea más fácil de entender y depurar en comparación con JPA o Hibernate, sobre todo si, nuevamente, dominas el lenguaje SQL.
- Menos dependencias: JDBC no tiene dependencias externas, lo que significa que no necesitas incluir ninguna biblioteca adicional en tu proyecto Java para usar JDBC. Esto puede hacer que tu proyecto sea más ligero y más fácil de manejar.
- Menos sobrecarga: como hemos visto, con JDBC tenemos muchas menos capas intermedias entre nuestra app y la base de datos, por lo que puede ser más rápido y más eficiente en términos de memoria que Hibernate u otros ORM JPA. Sin embargo esto no quiere decir que tenga mejor rendimiento siempre. Si tenemos en cuenta las cachés que ofrece Hibernate, por ejemplo, estas pueden hacer que las consultas ya cacheadas sean más rápidas, sin que tengamos que hacer nada.
Sin embargo, JDBC también tiene desventajas frente a un ORM:
- Puedes necesitar más código: dependiendo de lo que queramos hacer quizá tengamos que escribir más código y gestionar más detalles de bajo nivel en comparación con Hibernate o Spring Data JPA. Desde luego necesitaremos más código de "fontanería" para tareas comunes. Esto es especialmente cierto si queremos trabajar con objetos a partir de los datos obtenidos desde nuestra base de datos.
- Menor soporte para programación orientada a objetos: JDBC trabaja principalmente con resultados de consulta obtenidos en forma de conjuntos de resultados tabulares, lo que puede no ser ideal al trabajar con un lenguaje orientado a objetos como Java. De hecho esta discrepancia es el principal motivo por el que se inventaron los ORMs. Con Hibernate y similares trabajarás directamente con clases y objetos, facilitando la escritura, comprensión y mantenimiento del código.
- Menos funcionalidades: Hibernate y otros ORMs ofrecen muchas funcionalidades adicionales que no están disponibles en JDBC, como las ya mencionadas (mapeo objeto-relacional (ORM), caché de nivel 1 y 2, carga perezosa, optimización de consultas...).
- Menor portabilidad: JDBC requiere que escribas consultas SQL específicas para cada base de datos, ya que cada una tiene su propio dialecto del lenguaje. Un ORM, por regla general, proporciona una capa de abstracción entre tu código Java y las consultas SQL, generando el SQL adecuado para cada gestor de datos. Gracias a esto el código creado con Hibernate u otro ORM es más portable. Muchas veces consiste en cambiar el driver y listo. Esto es una ventaja crucial si realmente quieres tener independencia del gestor de datos.
En resumen
En este artículo hemos repasado las principales tecnologías relacionadas con la gestión de datos en Java, aclarando conceptos y mostrando sus relaciones y diferencias. En esencia tenemos que tomar una decisión importante entre dos formas de trabajar: usar JDBC para hacer acceso a datos a bajo nivel con SQL, más puro y con menos capas de abstracción, o utilizar un ORM que nos permite utilizar objetos y olvidarnos de SQL, aunque puede llegar a ser muy complejo también.
Al final, como era de esperar, la elección entre JDBC y Hibernate u otro ORM dependerá en gran medida del contexto y de las necesidades específicas de tu proyecto.
Para ayudarte a elegir, te dejo algunas recomendaciones y casuísticas en los que podría ser recomendable usar uno frente al otro:
- Proyectos pequeños y simples: si estás trabajando en un proyecto pequeño, no necesitas ninguna de las características adicionales que proporciona un ORM (sobre todo el mapeo objeto-relacional) y sabes hacer consultas SQL, entonces JDBC puede ser la opción más ligera y fácil de usar. Con JDBC, puedes tener un control total sobre tus consultas, lo que puede ser útil si necesitas realizar operaciones específicas que no son posibles o son más difíciles de realizar con Hibernate, y además tendrás mucho rendimiento y facilidad para leer el código, a costa de mucho código de "fontanería" que deberás escribir (como crear, abrir y cerrar las conexiones).
- Proyectos con requisitos de rendimiento muy altos: si tu aplicación necesita un alto rendimiento, la sobrecarga de un ORM puede llegar a ser un problema. En esos casos JDBC puede ser una mejor opción ya que puede ser más rápido y más eficiente en términos de memoria al no proporcionar funcionalidades adicionales, especialmente el mapeado a objetos.
- Aplicaciones complejas con muchas entidades: si vas a manejar muchas entidades que se almacenan en bases de datos y el rendimiento extremo no supone un problema, entonces un ORM es una buena elección, ya que te permite trabajar con tus objetos de forma natural, casi olvidándote de que estás usando una base de datos. De hecho, este es el caso más habitual y la principal razón de ser de un ORM, por lo que en muchas ocasiones te interesará utilizar uno de ellos. Eso sí, debes tener en cuenta que usarlo más allá de los casos habituales puede llegar a ser complejo.
- Proyectos con requisitos de portabilidad de almacén de datos: si necesitas que tu aplicación sea portátil entre diferentes bases de datos, un ORM puede ser la mejor opción. Hibernate (y por lo tanto Spring Data JDBC) proporciona una capa de abstracción entre tu código Java y las consultas SQL, generando en cada caso las apropiadas para cada base de datos, lo que puede hará que tu código sea mucho más fácil de transportar de una a otra.
En cualquier caso no te olvides de que, aunque aprendas un ORM sería muy importante aprender antes JDBC para entender que está ocurriendo por debajo.
¡Espero que esta información te resulte útil!