Para comunicarnos con una computadora debemos escribir programas. Pero los lenguajes de alto nivel que utilizamos (C, C++, C#, Java...) no son entendibles por la máquina, por lo que necesitamos un compilador que los traduzca a algo que la máquina pueda comprender. Este es el papel de los compiladores. Un compilador es simplemente un programa que traduce otros programas. LLVM es un proyecto de compilador de uso generalizado, consistente en muchas herramientas de compilación modulares. En este artículo vamos a ver en qué consiste un compilador, qué fases sigue y cómo funciona, desde un alto nivel para entenderlo mejor.

Nota: este artículo es una traducción de este post de Nicole Orchard con su permiso.
Un compilador es simplemente un programa que traduce otros programas. Los compiladores clásicos traducen código fuente a código máquina ejecutable que tu ordenador puede entender. (Algunos compiladores traducen código fuente a otro lenguaje de programación. Estos se denominan traductores fuente-a-fuente o transpiladores). LLVM es un proyecto de compilador de uso generalizado, consistente en muchas herramientas de compilación modulares.
El diseño tradicional de compiladores consta de tres partes:
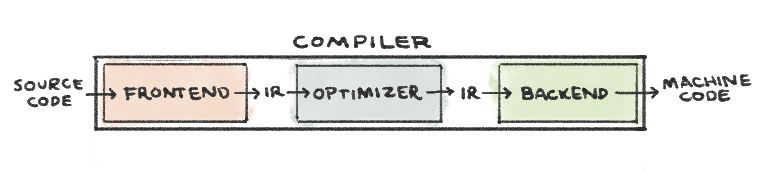
- El Frontend traduce código fuente en una representación intermedia (IR) de éste. LLVM IR es un lenguaje de bajo nivel parecido a ensamblador. Sin embargo omite cualquier información específica del hardware. clang es el frontend de LLVM para la familia de lenguajes de C.
- El Optimizador analiza la IR y la traduce a una forma más eficiente; opt es la herramienta de optimización de LLVM.
- ElBackend genera código máquina al mapear la IR al conjunto de instrucciones del hardware de destino; llc es la herramienta LLVM de backend.
Hola Compilador
A continuación se muestra un sencillo programa en C que imprime "¡Hola, compilador!" a stdout. La sintaxis de C es legible por el ser humano, pero mi computadora no sabría qué hacer con él. Vamos a repasar juntos las tres fases de compilación para hacer que este programa sea ejecutable por la máquina.
// compile_me.c
// Saluda al compilador. El resto puede esperar.
#include <stdio.h>
int main() {
printf("¡Hola Compilador!\n");
return 0;
}
El Frontend
Como he dicho anteriormente, clang es el frontend de LLVM para la familia de los lenguajes de C. Clang consiste en un preprocesador C, un analizador léxico, un analizador sintáctico, un analizador semántico y un generador IR.
- El preprocesador C modifica el código fuente antes de comenzar la traducción a IR. El preprocesador maneja la inclusión de archivos externos, como el
#include <stdio.h> de arriba. Reemplazará esa línea con todo el contenido del archivo de biblioteca estándar C stdio.h, que incluirá la declaración de la función printf que utilizamos más abajo.
Podemos ver el resultado de este paso del preprocesador ejecutando:
clang -E compile_me.c -o preprocessed.i
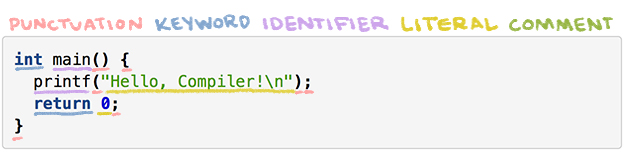
- El analizador léxico (también llamado lexer o escáner o tokenizador) convierte una cadena de caracteres en una cadena de palabras. Cada palabra, o token, se asigna a una de las cinco categorías sintácticas: puntuación, palabra clave, identificador, literal o comentario.
Tokenización de nuestro programa:
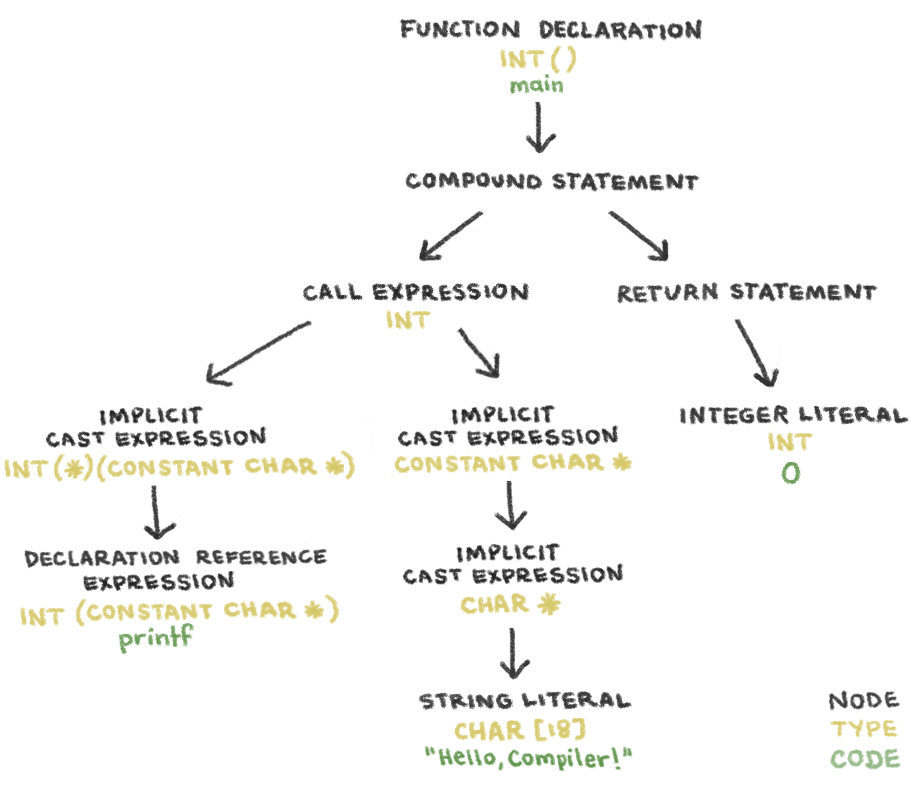
- El analizador sintáctico determina si la secuencia de palabras consiste en frases válidas en el idioma de origen. Después de analizar la gramática de la secuencia de fichas, emite un árbol de sintaxis abstracto (AST). Los nodos de un Clang AST representan declaraciones, sentencias y tipos.
El AST de nuestro programa:
-
El analizador semántico recorre el AST, determinando si las sentencias del código tienen un significado válido. Esta fase comprueba los errores de tipo. Si la función principal en nuestro código C devuelve "cero" en lugar de 0, el analizador semántico daría un error porque "cero" no es de tipo int.
-
El Generador IR traduce el AST a IR.
Si ejecutas el frontend de LLVM (clang) en el archivo .c anterior para generar LLVM IR:
clang -S -emit-llvm -o llvm_ir.ll compile_me.c
La función main en este archivo llvm_ir.ll sería:
; llvm_ir.ll
@.str = private unnamed_addr constant [18 x i8] c"¡Hola Compilador!\0A\00", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- memory allocated on the stack
store i32 0, i32* %1, align 4
%2 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([18 x i8], [18 x i8]* @.str, i32 0, i32 0))
ret i32 0
}
declare i32 @printf(i8*, ...)
El optimizador
El trabajo del optimizador es mejorar la eficiencia del código basándose en su comprensión del comportamiento en tiempo de ejecución del programa. El optimizador toma el IR como input y produce el IR mejorado como output. La herramienta optimizador de LLVM, opt, optimizará la velocidad del procesador con el flag -O2 (ojo, es una letra "o" mayúscula, no un cero) y optimizará para tamaño con el flag -Os (otra vez "O" mayúscula).
Échale un vistazo a la diferencia entre el código LLVM IR de nuestro frontend generado anteriormente y el resultado de ejecutar:
opt -O2 -S llvm_ir.ll -o optimized.ll
La función main en optimized.ll:
; optimized.ll
@str = private unnamed_addr constant [17 x i8] c"Hello, Compiler!\00"
define i32 @main() {
%puts = tail call i32 @puts(i8* getelementptr inbounds ([17 x i8], [17 x i8]* @str, i64 0, i64 0))
ret i32 0
}
declare i32 @puts(i8* nocapture readonly)
En la versión optimizada, main no asigna memoria en la pila, ya que no utiliza memoria alguna. El código optimizado también llama a puts en lugar de a printf porque no se utiliza ninguna funcionalidad de formato de printf.
Por supuesto, el optimizador hace más que sólo saber cuándo utilizar put en lugar de printf. El optimizador también desenreda bucles y mete en línea los resultados de cálculos simples. Mira el programa de abajo, que añade dos enteros e imprime el resultado:
// add.c
#include <stdio.h>
int main() {
int a = 5, b = 10, c = a + b;
printf("%i + %i = %i\n", a, b, c);
}
Aquí tenemos el LLVM IR no optimizado:
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i\0A\00", align 1
define i32 @main() {
%1 = alloca i32, align 4 ; <- allocate stack space for var a
%2 = alloca i32, align 4 ; <- allocate stack space for var b
%3 = alloca i32, align 4 ; <- allocate stack space for var c
store i32 5, i32* %1, align 4 ; <- store 5 at memory location %1
store i32 10, i32* %2, align 4 ; <- store 10 at memory location %2
%4 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %4
%5 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %5
%6 = add nsw i32 %4, %5 ; <- add the values in registers %4 and %5. put the result in register %6
store i32 %6, i32* %3, align 4 ; <- put the value of register %6 into memory address %3
%7 = load i32, i32* %1, align 4 ; <- load the value at memory address %1 into register %7
%8 = load i32, i32* %2, align 4 ; <- load the value at memory address %2 into register %8
%9 = load i32, i32* %3, align 4 ; <- load the value at memory address %3 into register %9
%10 = call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i32 0, i32 0), i32 %7, i32 %8, i32 %9)
ret i32 0
}
declare i32 @printf(i8*, ...)
Aquí tenemos el LLVM IR optimizado:
@.str = private unnamed_addr constant [14 x i8] c"%i + %i = %i\0A\00", align 1
define i32 @main() {
%1 = tail call i32 (i8*, ...) @printf(i8* getelementptr inbounds ([14 x i8], [14 x i8]* @.str, i64 0, i64 0), i32 5, i32 10, i32 15)
ret i32 0
}
declare i32 @printf(i8* nocapture readonly, ...)
Nuestra función principal optimizada es esencialmente las líneas 17 y 18 de la versión no optimizada, con los valores variables en línea. opt calculó la suma porque todas las variables eran constantes. Bastante guay, ¿no?
El Backend
La herramienta backend de LLVM es llc. Genera código máquina a partir del IR de LLVM en tres fases:
-
La selección de instrucciones es el mapeo de instrucciones IR al conjunto de instrucciones de la máquina de destino. Este paso utiliza un espacio de nombres infinito de registros virtuales.
-
La asignación de registros es el mapeo de registros virtuales a registros reales en tu arquitectura de destino. Mi CPU tiene una arquitectura x86, que se limita a 16 registros. Sin embargo, el compilador usará los menos registros posibles.
-
La programación de la instrucción es la reordenación de operaciones para reflejar las restricciones de funcionamiento de la máquina de destino.
La ejecución de este comando:
llc -o compiled-assembly.s optimized.ll
creará este código máquina:
_main:
pushq %rbp
movq %rsp, %rbp
leaq L_str(%rip), %rdi
callq _puts
xorl %eax, %eax
popq %rbp
retq
L_str:
.asciz "Hello, Compiler!"
Este programa es lenguaje ensamblador para x86, que es la sintaxis legible humana para el idioma en el que habla mi ordenador. ¡Alguien finalmente me entiende! 🙌
Libros para saber más:
Aquí tienes un resumen de este artículo en un solo gráfico (en inglés, pulsa para aumentar):
