El aprendizaje automático o machine learning puede emplearse para abordar distintos tipos de problemas. Estos pueden agruparse en categorías, según la clase de técnica con la que se acometa su resolución. El objetivo de este artículo es ofrecerte una visión general sobre los paradigmas de aprendizaje automático y los tipos de problemas para los que se usan habitualmente.

El aprendizaje automático o machine learning puede emplearse para abordar distintos tipos de problemas. Estos pueden agruparse en categorías, según la clase de técnica con la que se acometa su resolución.
El objetivo de este artículo es ofrecerte una visión general sobre los paradigmas de aprendizaje automático y los tipos de problemas para los que se usan habitualmente.
Paradigmas de aprendizaje automático
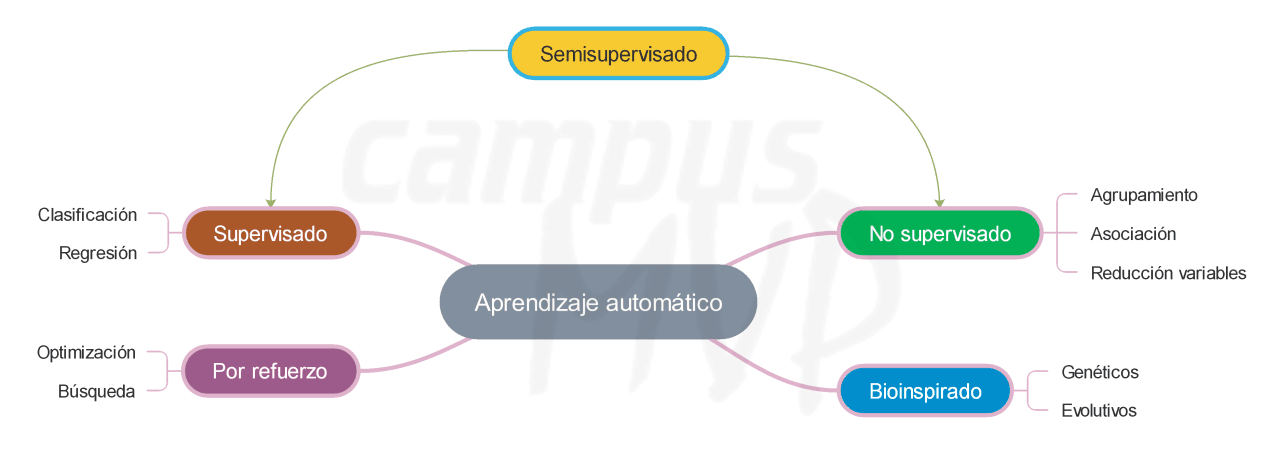
Por regla general (existen excepciones), los algoritmos de aprendizaje automático construyen un modelo que representa el conocimiento que han podido extraer de los datos que se le facilitan como entrada. Dependiendo de la información adicional que se suministre al algoritmo, a fin de guiar el proceso de aprendizaje, podemos diferenciar entre distintos paradigmas. A continuación te describo brevemente los más conocidos:
- Aprendizaje supervisado. Consiste en ir indicando al algoritmo, a medida que aprende, si la salida que ha generado para un cierto caso (la predicción) es correcta o no. La acción más corriente es que el algoritmo efectúe ajustes en el modelo que está generando cada vez que se le indica que se ha equivocado, con el objetivo de mejorar sus predicciones.
- Aprendizaje no supervisado. La única información que se entrega al algoritmo son las muestras de datos, sin más detalles. A partir de dichas muestras es posible analizar la distribución de los valores, la similitud o distancia entre las muestras, el grado de concurrencia de unas variables con otras, etc. Las aplicaciones son múltiples como comprobaremos después.
- Aprendizaje semisupervisado. Es un caso a medio camino de los dos anteriores. Del conjunto de datos con que se cuenta, se conoce la salida correcta solo para algunas muestras. El algoritmo las usa para construir un modelo inicial que, posteriormente, facilita una previsión del valor de salida para el resto de muestras. De esta forma, el modelo se amplía y ajusta aprovechando la información disponible.
- Aprendizaje por refuerzo. Al algoritmo al que se facilitan los datos no se le suministran las salidas reales para que pueda ajustar su modelo, como ocurre en el caso supervisado, pero se le otorga un premio más o menos grande en función de lo buena que es la secuencia de acciones llevada a cabo hasta el momento. De esta forma, el comportamiento se refuerza hacia el objetivo perseguido.
Cada uno de estos paradigmas permite resolver tipos específicos de problemas y puede ser implementado usando distintas herramientas: los modelos que representan el conocimiento. Dependiendo del modelo elegido: un árbol, una red neuronal, un conjunto de reglas, etc., se usará un algoritmo concreto para generarlo y ajustarlo.
Tipos de problemas en machine learning
El aprendizaje automático se emplea para resolver un gran abanico de problemas de la vida real. Dichos problemas, o tareas como también se las conoce, pueden ser categorizados en unos pocos tipos. Aunque no es una regla estricta, cada tipo de problema suele afrontarse mediante un paradigma concreto de aprendizaje. Por ello, a continuación se esbozan los tipos de tareas más corrientes atendiendo al paradigma con el que normalmente se aborda.
Tareas de aprendizaje supervisado
Existen dos tipos de problemas fundamentales que se resuelven mediante aprendizaje supervisado, descritos a continuación. Las salidas reales, conocidas de antemano para los datos, son las que permitirán al algoritmo ir mejorando los parámetros de su modelo. Una vez completado el aprendizaje o entrenamiento del modelo, este será capaz de procesar nuevas muestras y generar la salida adecuada sin ningún tipo de ayuda.
- Clasificación. Cada una de las muestras de datos tiene asociada una o más salidas nominales, a las que se denomina etiquetas de clase, etiquetas o sencillamente clase. Para clasificar de forma automática se crea un modelo predictivo, al que entregando las variables de entrada genere como salida las etiquetas de clase correspondientes. Un clasificador puede usarse para procesar solicitudes de préstamo en solventes o de riesgo, diferenciar los mensajes de correo entrantes como spam o importante, saber si en una fotografía aparece o no la cara de una persona, etc.
- Regresión. Como en el caso anterior, cada muestra también tiene asociado un valor de salida, pero en este caso es de tipo real (continuo, no discreto, es decir, con posibles resultados dentro de un continuo), por lo que las técnicas empleadas para generar el modelo son habitualmente distintas a las usadas para clasificación. No obstante, el procedimiento de ajuste o entrenamiento del modelo es similar: se usan las salidas reales conocidas para corregir sus parámetros y mejorar la predicción. Con un modelo de regresión es posible determinar la estatura de una persona en función de su sexo, edad y nacionalidad, o predecir la distancia que podrá recorrer un transporte tomando como variables de entrada el peso de la carga, volumen de combustible disponible y temperatura ambiente.
Tareas de aprendizaje no supervisado
Los tipos de problemas afrontados con este paradigma de aprendizaje se caracterizan, como se ha indicado más arriba, porque las muestras de datos solo cuentan con las variables de entrada. No hay una salida a predecir que pueda guiar a los algoritmos. Por ello, los modelos generados, en caso de existir, no son predictivos sino descriptivos. Las tareas más comunes son las siguientes:
- Agrupamiento. Analizando la similitud/disimilitud de las muestras de datos, por ejemplo, calculando la distancia a que se encuentran unas de otras en el espacio generado por los valores de sus variables, se crean varios grupos disjuntos. Esta técnica, también conocida como clustering, facilita la exploración visual de los datos, pudiendo emplearse también como un método de clasificación básico cuando no se dispone de las etiquetas de clases necesarias para generar un clasificador.
- Asociación. La búsqueda de asociaciones entre ciertos valores de las variables que componen las muestras se efectúa buscando la concurrencia entre ellos, es decir, contando las veces que aparecen simultáneamente. Este tipo de problema puede generar como resultado un conjunto de reglas de asociación, siendo una técnica muy empleada en todo tipo de comercios, tanto electrónico como físico, para disponer sus productos o recomendarlos.
- Reducción de variables. Mediante el análisis de la distribución de los valores de las variables en el conjunto de muestras, es posible determinar cuáles de ellas aportan más información, cuáles están correlacionadas con otras y por tanto son redundantes o si es posible encontrar una distribución estadística subyacente que genera esos datos, lo cual permitiría simplificar su representación original. En este tipo de tarea existen multitud de técnicas posibles, desde la selección y extracción de variables hasta lo que se denomina manifold learning, consistente en encontrar la citada distribución subyacente.
Nota: de los citados aquí, los algoritmos de agrupamiento y de asociación generarían un modelo descriptivo. En el primer caso aportaría información sobre la forma en que se agrupan las muestras de datos, la distancia que hay entre muestras de un mismo grupo y lo diferentes que son respecto a muestras de otros grupos. En el segundo, las reglas y métricas asociadas a ellas conforman un modelo que permite conocer casuísticas específicas del problema analizado.
Otros tipos de tareas de aprendizaje
Una gran mayoría de los problemas abordables mediante aprendizaje automático pertenecen a las categorías enumeradas en los dos apartados previos. No obstante, existen otros tipos de tareas que precisan de enfoques diferentes. Un ejemplo serían los problemas de optimización en general, de los cuales quizá el exponente más conocido es el del viajante del comercio. Esta tarea consiste en buscar el itinerario más corto para visitar n ciudades. En el momento en que n es muy grande el problema se vuelve inabordable a la búsqueda exhaustiva: evaluar todas las posibles alternativas para determinar la mejor.
Existen muchos otros casos dentro de esta categoría y la dificultad suele ser siempre la misma: no se conoce el caso óptimo, por lo que no puede saberse si una potencial solución es más o menos buena, y el número de posibles soluciones, o de pasos para llegar hasta ellas, es enorme. Existen dos categorías de técnicas que suelen aplicarse para afrontar estos problemas:
- Algoritmos bioinspirados. Forman parte de este grupo los algoritmos genéticos, estrategias evolutivas, optimización basada en sistemas de partículas, etc. Todos ellos parten de un mismo concepto: reproducir mecanismos existentes en la naturaleza como puede ser la selección evolutiva en los seres vivos, el comportamiento de bandadas de pájaros, de colonias de hormigas, etc. Gracias a ellos es posible encontrar una solución aceptable al problema de optimización en un lapso de tiempo razonable.
- Aprendizaje por refuerzo. Este paradigma, descrito al inicio del apartado, puede aplicarse también a problemas de optimización, si bien en los últimos tiempos ha ganado notoriedad por su éxito a la hora de aprender a jugar y ganar determinados juegos, desde el Super Mario Bros a ajedrez o Go.
Como puedes comprobar, existen multitud de problemas que pueden ser resueltos mediante el aprendizaje automático.
El primer paso suele ser determinar la categoría del problema que se afronta para, a continuación, seleccionar el paradigma de aprendizaje más adecuado. Estos dos factores nos permitirán, en un paso posterior, elegir la herramienta de trabajo más adecuada.