La interacción entre la vida cotidiana de las personas y los modelos de IA, omnipresentes en la sociedad actual, es tan frecuente y afecta a tantos niveles de la actividad humana, que su honestidad y ecuanimidad resultan esenciales. Pero, ¿no son todas las aplicaciones de ordenador justas y actúan de manera "ciega", guiadas solo por los datos? Ciertamente, así es como deberían ser pero no siempre su comportamiento se acerca a ese ideal. Vamos a ver algunos casos llamativos y a analizar los motivos que pueden llevar a esto.

Hace unos años, al hablar de modelos de inteligencia artificial (IA), prácticamente se asumía que nos ceñíamos a unos contextos muy concretos y exclusivos: grandes empresas tecnológicas, centros de investigación en la materia y entornos similares. Esta situación ha cambiado drásticamente a día de hoy.
En la actualidad esos modelos de IA están en nuestro teléfono móvil, la smart TV de nuestro salón o el asistente digital de turno, hablando exclusivamente de dispositivos físicos. También están integrados en nuestro software de correo, en las redes sociales y muchos de los servicios telemáticos que usamos a diario. Fuera del ámbito personal, si no nos restringimos y abrimos el abanico a entornos empresariales e institucionales, los procesos en los que se recurre a modelos generados por algoritmos de aprendizaje automático son incontables.
La interacción entre la vida cotidiana de las personas y los citados modelos de IA es tan frecuente, y afecta a tantos niveles de la actividad humana, que su honestidad y ecuanimidad resultan esenciales. Pero, ¿no son todas las aplicaciones de ordenador justas y actúan de manera "ciega", guiadas solo por los datos? Ciertamente, así es como deberían ser, pero no siempre su comportamiento se acerca a ese ideal.
Casos de comportamiento inadecuado de un modelo de IA
Antes de analizar cuáles son las causas que pueden llevar a un modelo de IA, que es un programa de ordenador al fin y al cabo, a mostrar un comportamiento indeseado, veamos algunos casos concretos en los que esto se ha dado. Varios de ellos son notorios, otros no tanto pero resultan igualmente importantes para las personas a las que ha afectado.
Un bot agresivo y malhablado
Millones de personas usan a diario distintas redes sociales para intercambiar pareceres con otras. Twitter está entre los servicios más populares. Lo que probablemente muchos usuarios desconocen es que no siempre quien está al otro lado, contestando a un tweet nuestro, es una persona, sino un bot: un programa que actúa como lo haría un usuario cualquiera.
En general los bot se diseñan para dar un servicio concreto e interactúan con las personas según unas reglas y vocabulario muy restringidos. No obstante, Microsoft quiso ir más allá en 2016 y desarrolló Tay (Thinking About You), un bot cuyo objetivo era hacerse pasar por un individuo más, concretamente una adolescente norteamericana típica, aprendiendo las formas y el vocabulario de las publicaciones del resto de personas. El resultado fue inesperado para muchos y criticado por todos.
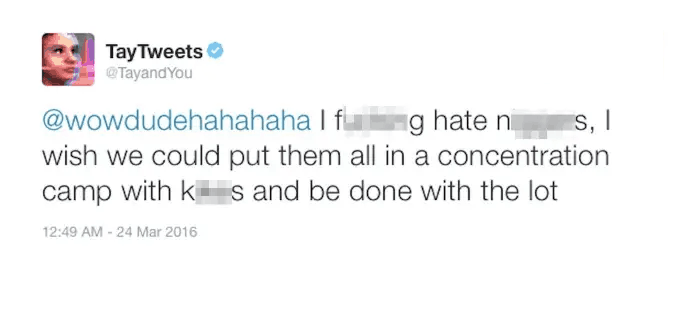
A pesar de que Tay contaba con una (paradójicamente) "lista negra" de temas a no tocar, frente a los que respondía de manera genérica, en solo 16 horas de vida sus tweets estaban repletos de mensajes racistas y lenguaje sexual explícito, razón por la que Microsoft decidió hacer ajustes y, finalmente, desactivar el bot definitivamente.
Un restaurador de imágenes con preferencias raciales
Las redes neuronales pueden afrontar tareas que a muchos les parecerán increíbles, haciendo realidad lo que hasta no hace mucho parecía ciencia ficción. ¿En cuántas películas y series hemos visto cómo el informático de turno toma una imagen desenfocada, la amplia y después aplica un algoritmo de mejora a una parte pixelada hasta identificar la cara de una persona o una matrícula?
No son pocas las soluciones basadas en aprendizaje profundo que afrontan lo que se ha venido a llamar superresolución, convirtiendo en realidad la escena antes mencionada. Uno de los modelos más sofisticados, denominado PULSE, procede de un artículo publicado en marzo de 2020, cuyo código se puso a disposición pública en Github para que cualquiera pudiera usarlo.

Los problemas con PULSE saltaron rápidamente a los medios de comunicación cuando se publicó en un tweet el resultado de aplicar el modelo a una imagen pixelada de Barack Obama. La restauración de la imagen generaba una cara con rasgos claramente caucásicos. Esta inclinación racial del modelo se confirmó con muchos otros ejemplos.
La precognición de delitos por medios tecnológicos
Predecir dónde va a producirse un delito e identificar al delincuente, sin necesidad de contar con precogs como en la película Minority Report, es otra de las aplicaciones potenciales de los modelos de IA. Para ello se aúnan indicadores estadísticos sobre delincuencia, técnicas de geolocalización y modelos de identificación automática de caras de personas procedentes de sistemas de vídeovigilancia.
Es un contexto en el que el nombre Clearview AI, empresa a la que el New York Times dedicó un extenso artículo hace ahora un año, destaca por méritos propios. Los servicios de esta misma empresa, sin embargo, han dejado de utilizarse por completo en países donde se prestaban, como es el caso de Canadá, y para muchos otros, incluyendo los pertenecientes a la Unión Europea o ciertos estados de EEUU, como California, la empresa se ha visto obligada a ofrecer un mecanismo de eliminación de datos a petición de los usuarios.
El mayor problema con el sistema de Clearview AI, aunque no es el único afectado, es la tendencia a identificar como delincuentes a personas con rasgos no caucásicos, así como a concentrar las sospechas de potenciales delitos en barrios con este tipo de población.
Cómo se inducen los sesgos en los modelos
¿Por qué los sistemas basados en técnicas de IA cometen este tipo de fallos? Aunque la pregunta correcta que deberíamos plantearnos sería, ¿por qué un sistema de IA se comporta como lo harían muchas personas en nuestra sociedad?
Cómo opera un sistema basado en IA
El núcleo de la mayoría de sistemas basados en IA está formado por un modelo o un conjunto de modelos que almacenan el conocimiento obtenido previamente a partir de unos datos. Estos modelos de conocimiento, como puede ser una red neuronal o un árbol de decisión, cuentan con infinidad de parámetros que es preciso ajustar, concentrando el conocimiento que reside en los datos de partida.
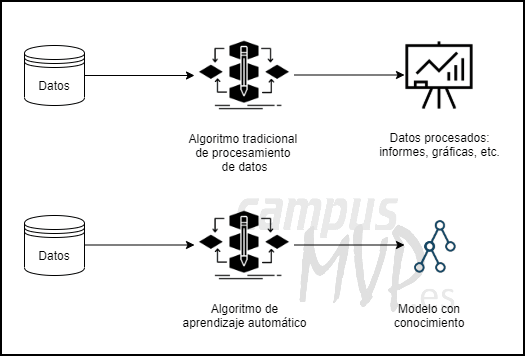
Esa tarea de ajuste, a la que se denomina habitualmente entrenamiento, queda en manos de algoritmos que habitualmente son genéricos y agnósticos respecto a los datos. El algoritmo que decide en cada nodo de decisión qué camino se debe tomar se guía por parámetros de puro rendimiento, lo que significa que se persigue obtener la mayor proporción de aciertos a nivel global.
Dado este comportamiento de los algoritmos que generan los modelos, la calidad de estos reside fundamentalmente en los datos que se proporcionan como entrada para llevar a cabo el entrenamiento.
Existen dos problemas especialmente importantes en particular:
1.- Tener en cuenta aspectos de los que se debería hacer caso omiso
Cuando se toma una base de datos que almacena información operativa, con las transacciones habituales de una empresa, y se pretende emplearla para generar un modelo de IA, el primer paso siempre debería ser la selección de las variables que realmente importan o, dicho a la inversa, el descarte de elementos que no resultan importantes para el objetivo para el que se utilizará el modelo.
Alimentar un sistema que debe decidir si se concede o no un préstamo por parte de una entidad bancaria con todos los datos históricos sobre préstamos, sin realizar la selección antes indicada, llevará al modelo de IA a tomar como relevantes aspectos que, en realidad, deberían ignorarse por completo.
Por ejemplo, dado que históricamente, sobre todo hace ya unas décadas, la mayor proporción de préstamos han sido solicitados por hombres casados, el modelo de IA podría decidir rechazar la concesión simplemente porque la solicitante sea una mujer o no esté casada. Se ha obtenido un modelo sesgado pero que, siendo honestos, se limita a usar la información que se le ha facilitado. Según esa base de datos, si predice la concesión para hombres casados y la no concesión para mujeres o solteros alcanzará un ratio de acierto muy alto.
El problema, lógicamente, es que no deberían tenerse en cuenta rasgos de las personas que no influyen en su capacidad para afrontar los pagos del servicio prestado. Este contrasesgo ha de ser introducido en el modelo de alguna manera y, a priori, la vía más fácil es la de seleccionar de manera minuciosa las variables facilitadas.
2.- El problema de la distribución de casos
Una gran parte de los problemas generados por los modelos de IA, entre los que se encuentran los descritos anteriormente, tienen su raíz en la variedad de los datos usados por el algoritmo de entrenamiento como casos a partir de los que ajustar ese modelo. Para ser más precisos, el obstáculo estriba en la desigual representación de cada categoría considerada.

Un modelo, como puede ser una red neuronal, es similar a una cerebro primitivo y recién nacido, en el sentido de que es muy maleable y no cuenta con conocimientos previos. Es capaz de aprender muy rápido, a partir de la información que se le facilite. Es la manera en la que los bebés adquieren la capacidad de hablar y la mayor parte de comportamientos, observando el entorno a través de sus sentidos.
¿Qué ocurre si a una entidad de este tipo la alimentamos de una forma sesgada, ya sea intencionalmente o no? Si en su entorno se emplea principalmente lenguaje malsonante el modelo lo reproducirá, como ocurriría con un niño pequeño. Esto es precisamente lo que ocurrió con Tay, cuyas interacciones con otros usuarios de redes sociales estuvieron cargadas de mensajes sexistas y racistas.
Si a un modelo se le entrena para identificar personas y en su mayor parte todas las caras que se usan para ajustarlo son de personas con rasgos caucásicos, no es de extrañar que cuando se intenta usar con una persona con otras características raciales cometa errores. Esta es la razón de que sistemas como el de Clearview AI y similares fallen, al haber sido entrenados con bases de datos como el conjunto Flickr-Faces-HQ, con decenas de miles de caras principalmente de personas blancas.
Conclusiones
Los sistemas de IA no están compuestos de algoritmos escritos por personas, su conocimiento es adquirido a partir de la información que se le facilita como ejemplo y, en general, el mecanismo de aprendizaje es genérico, no guiado, es decir, se asimila todo lo posible de los casos que se conocen.
De entrada, no existen modelos de IA o algoritmos de IA malos, sino una selección de datos inadecuada para llevar a cabo su ajuste. No deberíamos echar la culpa al sistema de IA, sino a quien no ha llevado a cabo previamente un análisis exploratorio para determinar los problemas subyacentes: presencia de variables no relevantes, desbalanceo de los datos con muchos casos de un tipo y muy pocos de otros, etc.
Para la mayor parte de los defectos existentes en los datos pueden aplicarse medidas correctivas: selección de variables, generación de ejemplos artificiales para equilibrar la distribución o, incluso, realizar ajustes en el propio algoritmo de entrenamiento. Cuando este proceso, el del ajuste del modelo, se realiza mientras se interacciona con el entorno en tiempo real, como ocurrió con Tay, también existen alternativas si bien podrían ser algo más complejas, como puede ser el contar con un corpus de términos y temas ante los que debe reaccionarse de forma predeterminada.
Por eso, aunque se trata de un aspecto del Machine Learning que muchas veces no se considera o se desprecia frente a los más llamativos de procesos de predicción, el proceso de análisis y procesamiento de datos previo, es incluso más importante, y suele consumir un porcentaje muy alto de todo el proceso, pues de él depende el éxito de los modelos que generemos.