Todas las empresas, en mayor o menor medida, manejan múltiples fuentes de información útil. Generalmente esta información se almacena en bases de datos, pero también en otro tipo de almacenes, como por ejemplo hojas de cálculo o archivos CSV. Todas esas fuentes de datos contienen información útil y permiten obtener mucho conocimiento a partir de ellas. Pero el proceso para lograrlo no es sencillo ni directo. La transformación de esos datos en información útil, es decir, en conocimiento, requiere de un proceso que puede llegar a ser complejo. En este artículo te contamos en qué consiste y de qué fases consta.
Hace unas semanas presentábamos en un artículo previo distintos conceptos relacionados con el campo de la inteligencia artificial (IA), entre los cuales se mencionaba brevemente el término KDD (Knowledge Discovery in Databases o descubrir conocimiento en las bases de datos), que es parte de la ciencia de datos. El objetivo de este artículo es explicar en qué consiste KDD y, al tiempo, cómo se relaciona con otros términos.
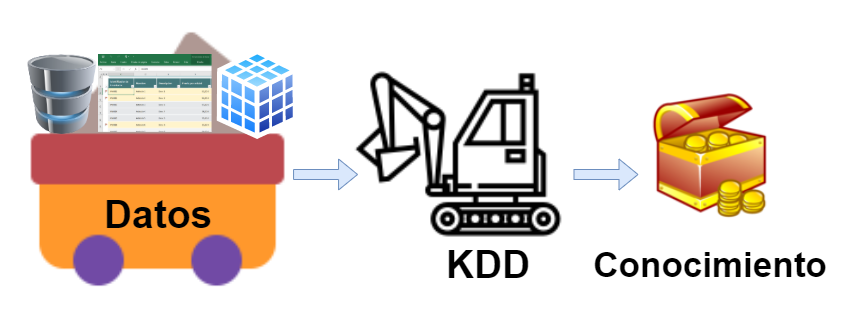
El acrónimo KDD hace referencia a un proceso, compuesto de múltiples etapas, cuyo objetivo principal es la extracción de conocimiento, que ha de resultar útil y no ser trivial, a partir de los datos a los que se tiene acceso.
Terminología relacionada
El proceso de KDD está estrechamente relacionado con el aprendizaje automático o machine learning (ML) y también con la minería de datos o data mining (DM). Son términos que, en ocasiones, llegan a confundirse y utilizarse de manera indistinta.
Para algunos expertos, KDD y DM son sinónimos, mientras que para otros DM es una de las fases del KDD. Ambos conceptos tienen casi un siglo de existencia y llevan implícita la intervención manual del experto a la hora de preparar los datos en los cuales se espera encontrar el conocimiento al que se hacía mención antes.
En lo que sí hay coincidencia es en que las técnicas de ML son posteriores en el tiempo a KDD y DM, y se centran más en la construcción de los algoritmos que en la preparación de los datos en sí. La finalidad de un algoritmo de ML es, tomando como entrada patrones de datos, generar un modelo que contiene el conocimiento extraído.
Existe un campo completo de estudio relativo a la forma de representar el conocimiento desde una perspectiva abstracta, usando para ello modelos que pueden tomar diferentes formas. Ejemplos de representaciones habituales serían el grafo, con nodos y conexiones entre ellos, y el árbol.
Fases del proceso de KDD
Atendiendo a la visión que fija la minería de datos como parte del KDD, este proceso constaría de las fases que se observan en el siguiente esquema:
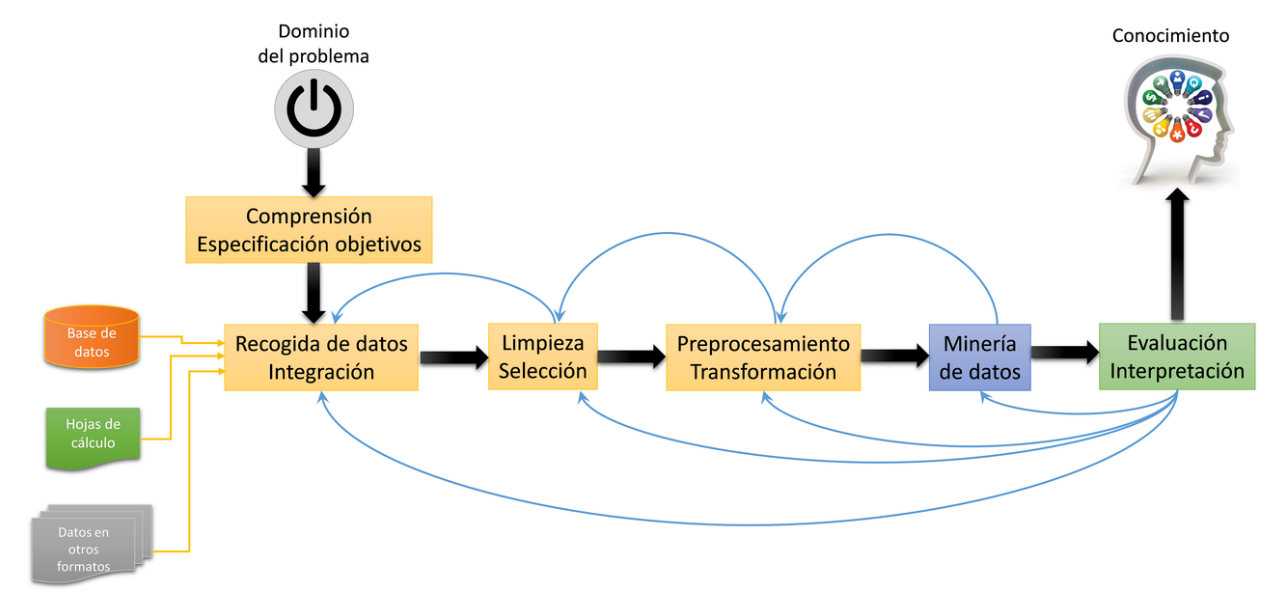
El esquema debe leerse de izquierda a derecha, comenzando por la comprensión del dominio al que corresponden los datos que van a emplearse y la especificación de los objetivos que se persiguen.
Tradicionalmente los datos proceden de sistemas OLTP (On-Line Transaction Processing, procesamiento de transacciones en línea), con bases de datos relacionales diseñadas para el registro continuo de datos más que para su análisis, como por ejemplo una base de datos de gestión, o de ventas en un comercio electrónico. También es habitual contar con datos en otros tipos de recipientes, como pueden ser hojas de cálculo.
La heterogeneidad de formatos, representaciones, unidades de medida y, en general, estructura de los datos, representa un obstáculo en el proceso de extracción de información a partir de los mismos.
La primera etapa del KDD consiste en recopilar los datos de todas esas fuentes y homogeneizarlos e integrarlos, produciendo lo que se conoce como conjunto de datos o dataset. Esta es una base de datos con un formato unificado y, además, con una estructura más adecuada para el análisis de los datos.
Etapas de preprocesamiento
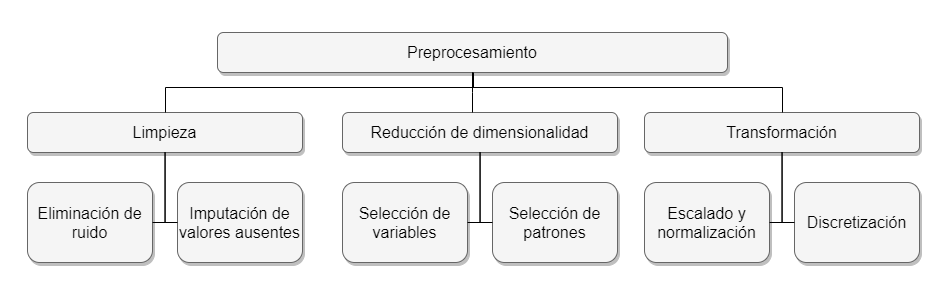
El trabajo de preparación de los datos no se limita a la integración y homogeneización, sino que abarca varias tareas más que suelen incluirse bajo la denominación genérica de preprocesamiento de datos. Entre estas, las más habituales son:
- Limpieza de los datos: durante la recogida de datos, ya sea esta manual o automática, así como en su posterior codificación y transmisión hasta llegar a formar parte del conjunto de datos, es habitual que se produzcan errores. Estos se traducen normalmente en dos tipos de problemas. El primero viene dado por datos que son claramente erróneos y, por tanto, introducirían ruido en el proceso de extracción de conocimiento en lugar de resultar útiles. El segundo estriba en la pérdida de algunos datos, casuística que dejaría huecos en el conjunto de datos. Las tareas de limpieza de datos, por ejemplo mediante algoritmos de eliminación de ruido o de imputación de valores ausentes, abordarían estos obstáculos.
- Selección de datos relevantes: no todos los datos obtenidos de las fuentes originales son necesariamente relevantes para el KDD, por lo que la selección de aquellos que realmente son útiles es otro paso más en el preprocesamiento. Dos de las tareas más usuales en esta fase son la selección de variables y la selección de patrones. Esencialmente consisten en eliminar aquellos datos que, por estar repetidos o pueden estimarse a partir de otros, no aportan mejora en la extracción de conocimiento. Estas dos técnicas forman parte de los métodos de reducción de dimensionalidad.
- Transformación de los datos: una vez que los datos están limpios y no contienen redundancias, aspectos de los que se ocupan las operaciones previas, podría pensarse que ya pueden usarse para el aprendizaje de un modelo. No obstante, hay acciones que podrían mejorar los datos de cara a hacer más efectivo ese aprendizaje. Entre ellos están la normalización, el escalado y la discretización. Se trata de operaciones que transforman los datos originales, casi siempre de manera reversible, produciendo una nueva versión más conveniente para el análisis KDD.
La fase de minería de los datos
Tras el preprocesamiento, los datos están preparados para la siguiente fase. En esta se usa un algoritmo de minería de datos a fin de extraer de estos el conocimiento que no resulta obvio ni es trivial, aunque esté implícito en ellos.
Existen multitud de métodos que es posible aplicar en este punto, incluyendo diversas técnicas estadísticas, algoritmos matemáticos de optimización y, por supuesto, métodos de Machine Learning.
A diferencia de en los pasos previos, donde se requiere una exploración de los datos que determine qué operaciones es preciso llevar a cabo y la intervención del experto es imprescindible, en la fase de minería de datos es donde suele recurrirse al Machine Learning.
Un algoritmo de aprendizaje automático procesa los datos y lo que genera como salida no son nuevos datos, como es habitual en la mayoría de algoritmos de ordenador, sino un modelo que representa el conocimiento extraído:
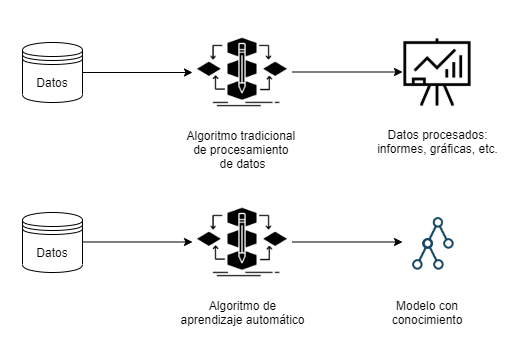
Este modelo resultante puede tener distintas aplicaciones:
- Modelos descriptivos: para describir la estructura subyacente de los datos
- Modelos predictivos: sirviendo para realizar predicciones en el futuro
- Base de reglas: convirtiéndose en los cimientos de un sistema de apoyo a la toma de decisiones.
Evaluación y vuelta atrás
Como puede apreciarse en el esquema que resume el proceso de KDD, prácticamente todos los pasos cuentan con una conexión hacia atrás que identifica su naturaleza iterativa. Ese retorno a pasos previos tiene múltiples destinos en la fase final de evaluación e interpretación del conocimiento que se ha obtenido.
Dependiendo del tipo de modelo que se haya generado y de cuál sea su finalidad, hay disponibles diferentes conjuntos de métricas que permiten medir cómo de bueno es ese modelo. La mayor parte de esas medidas están acotadas, es decir, facilitan valores entre un intervalo conocido, por lo que es posible determinar si el conocimiento extraído es útil o no de manera inmediata.
Las métricas usadas con modelos ML evalúan su rendimiento en una tarea concreta, por ejemplo a la hora de realizar predicciones, y también facilitan la comparación de diferentes modelos a fin de determinar cuál es mejor.
En función del rendimiento obtenido, y del análisis efectuado para determinar qué problemas plantea el modelo, sería preciso realizar ajustes en el algoritmo de Aprendizaje Automático (ML) o bien introducir cambios en los pasos previos de preprocesamiento y preparación de los datos.
Volumen de trabajo de las fases del KDD
El proceso de KDD, en el que se basan la mayor parte de los proyectos de Inteligencia Artificial que implican aprender a partir de datos existentes y, en consecuencia, el uso de algoritmos de Machine Learning, conlleva un volumen de trabajo considerable. Este, no obstante, no se reparte por igual entre las distintas fases.
Se considera que las fases de preparación y preprocesamiento de los datos consumen entre un 80% y un 90% del tiempo total dedicado a la extracción de conocimiento. Son pasos que precisan una intervención manual del experto y una supervisión minuciosa a la hora de decidir qué operaciones se aplican, según la naturaleza y estructura de los datos. Además, es frecuente tener que volver atrás entre sus etapas, realizando los ajustes apropiados hasta conseguir un conjunto de datos apropiado como entrada para la fase de minería de datos.
El paso en que el que se alimenta el algoritmo de ML con ese conjunto de datos, en parte debido a los enormes avances en potencia de procesamiento, comparativamente suele precisar muy poco tiempo. Lógicamente depende de la cantidad de datos con que se cuente y la complejidad del modelo producido, pero en muchos casos la respuesta se obtiene en pocos minutos.
Esperamos que tras leer este artículo hayas obtenido una visión general sobre qué es el proceso de KDD, cuál es su objetivo y las fases de que consta.
Muchos de los sistemas actuales de IA, aplicados en multitud de escenarios como te contábamos en 5 aplicaciones prácticas inesperadas de la Inteligencia Artificial, están basados en dicho proceso.