La máxima más famosa en Machine Learning y, en general, en todas aquellas disciplinas que se fundamentan en el uso de datos es: "Si entra basura, sale basura". Y es que no sólo llega con tener algoritmos buenos: hay que tener también datos buenos. Si no realizamos un análisis exploratorio previo de los datos podemos encontrarnos con muchos problemas y puede hacer que el algoritmo elegido sea mucho menos efectivo... Además puede aportarnos información muy relevante. Te lo explicamos con un ejemplo...

La máxima más famosa en Machine Learning y, en general, en todas aquellas disciplinas que se fundamentan en el uso de datos es: "Si entra basura, sale basura". Y es que no sólo llega con tener algoritmos buenos: hay que tener también datos buenos. Ya hemos hablado aquí por ejemplo de los sesgos en los datos y sus peligros, pero es que hay muchas otras circunstancias negativas en los datos que son mucho menos sutiles y que debiésemos detectar.
Por supuesto, el objetivo final de las disciplinas de Inteligencia Artificial es que crear modelos de aprendizaje automático a partir de un conjunto de datos, y que estos modelos extraigan el conocimiento útil de forma autónoma, y el estudio del análisis exploratorio puede parecer muy aburrido. Es por eso que muchas formaciones de Machine Learning lo dejan de lado, lo cual es un error.
A priori, realizar un análisis exploratorio sobre unos datos que posteriormente vamos a procesar mediante un programa puede parecer superfluo. Sin embargo, los algoritmos de aprendizaje no son infalibles, y como he comentado requieren que les proporcionemos los datos lo más limpios que sea posible.
Si no llevamos a cabo un análisis exploratorio de calidad, podemos encontrarnos con algunos problemas, entre otros:
-
Valores incorrectos en algunas variables que pueden deberse a malas mediciones o errores de anotación y que alterarán el comportamiento de un modelo de aprendizaje.
-
Variables que son idénticas o están muy relacionadas, de forma que no aportan información nueva sino redundante.
-
Variables que no tienen relación con el propósito de nuestro análisis, como identificadores únicos sin significado, fechas o con el mismo valor para todas las muestras.
Aunque parezcan pequeños inconvenientes fáciles de resolver, si no los tratamos podemos encontrarnos con modelos cuyo rendimiento sea mucho peor del esperado. Esto es debido a que, por lo general, los algoritmos de aprendizaje no son capaces de discernir qué datos consideramos válidos y útiles y cuáles no.
Además, con una exploración más a fondo del conjunto de datos podremos obtener intuiciones sobre muchas cuestiones, como:
- qué modelo de aprendizaje funcionará mejor
- qué variables nos sirven realmente y cuáles podemos eliminar
- cómo recuperar los datos que hayan sido incorrectamente anotados o no anotados...
El análisis exploratorio en ocasiones también puede aportarnos información muy relevante sobre los datos, sin llegar a aplicar un modelo. La distribución de los valores de una variable visualizada en un histograma o las correlaciones entre las variables y la clase, en una gráfica de correlaciones, resultan útiles por sí mismas y nos pueden ayudar a tomar algunas decisiones.
Un ejemplo sencillo pero muy aclarador
Consideremos un caso en el que tenemos dos versiones de un mismo conjunto de datos: una versión limpia y una versión sin limpiar, con algunos errores en valores y variables inútiles. El propósito de este conjunto de datos es tratar de estimar el precio final de un coche de segunda mano dadas algunas de sus características y el kilometraje.
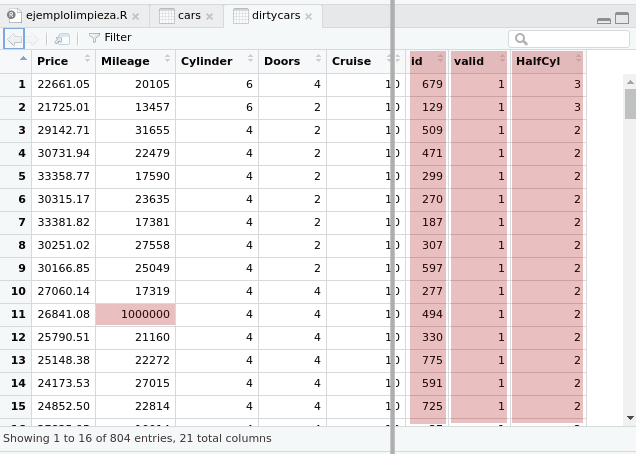
En la siguiente figura podrás observar que, a la izquierda, el conjunto de datos contiene:
- Valores extremos, como por ejemplo 1.000.000 en
Mileage (que indicaría que se ha recorrido un millón de millas con ese coche, más de un millón seiscientos mil kilómetros)
- Columnas como:
Id que contiene un identificador aleatorioValid que simplemente contiene 1HalfCyl que equivale a la mitad de Cylinder.
A continuación, tenemos el conjunto ya limpio, donde los valores extremos se han sustituido por un valor más adecuado, y las columnas inservibles se han eliminado:
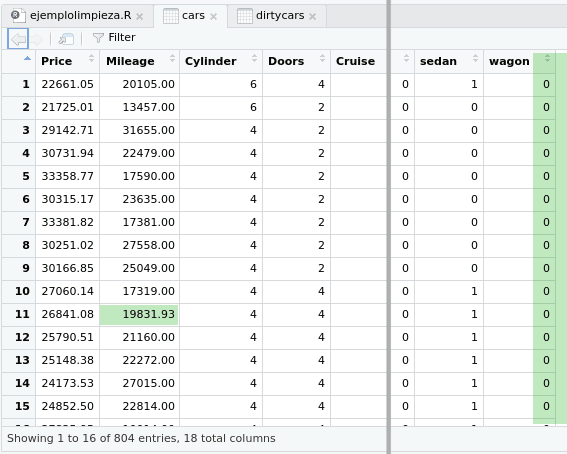
OJO: en este ejemplo no explicamos cómo se ha realizado el análisis y la limpieza de los datos, ni cómo se han entrenado los modelos de predicción del precio de coches. El objetivo es tan solo que te sirva para ver el efecto del análisis exploratorio.
Para comprobar si nuestro proceso de limpieza ha tenido éxito, vamos a utilizar una técnica de aprendizaje para obtener modelos que se hayan entrenado con los datos sin limpiar y los datos limpios. Una vez entrenados, evaluamos cada uno calculando una métrica que nos da idea del error típico del modelo (valores más bajos indican mejor rendimiento):
> # Evaluamos mediante el error cuadrático medio
> RMSE(cleanpred, cars$Price[testidx])
[1] 2038.236
> RMSE(dirtypred, cars$Price[testidx])
[1] 2702.444
La variable cleanpred del listado anterior contiene las predicciones de precios según el modelo de datos limpios para una lista nueva de coches que el modelo no conoce, y análogamente para el modelo de datos sin limpiar en la variable dirtypred. Como ves, el error en este último caso es mucho mayor (del orden de un 33% mayor), por lo que podemos decir que, al limpiar el conjunto de datos, nuestro error se reduce en un 25%.
Esta mejora viene dada únicamente por la calidad de los datos, ya que el algoritmo que se ha usado para obtener un modelo es exactamente el mismo en ambos casos.
Incluso en un ejemplo con datos tan simples como estos puedes observar la enorme importancia que tiene el análisis exploratorio.