En los dos últimos años, sobre todo, los microservicios se han convertido en un tema muy popular. La 'locura de los microservicios' viene a ser algo así: "Los de Netflix son buenísimos en devops. Netflix hace microservicios. Por lo tanto: si yo hago microservicios, seré buenísimo en devops."
Hay muchos casos en los que se ha hecho un gran esfuerzo en adoptar patrones de microservicios sin realmente comprender cómo los costes y los beneficios se aplican a las especificaciones del problema que se tiene entre manos. En este artículo vamos a describir en detalle qué son los microservicios, por qué el patrón es tan atractivo, y también cuáles son los desafíos fundamentales que conllevan. Terminaremos con un conjunto de preguntas que pueden servir para preguntarte a ti mismo cuando estás valorando si los microservicios son un patrón apropiado para ti. Las preguntas están al final del artículo.
Nota: este artículo es una traducción del original "The Death of Microservice Madness in 2018" escrito por Dave Kerr y con el permiso expreso del autor. Algunos enlaces y notas se los hemos añadido nosotros para dar más contexto y que se entiendan mejor algunos conceptos.
En los dos últimos años, sobre todo, los microservicios se han convertido en un tema muy popular. La 'locura de los microservicios' viene a ser algo así:
Los de Netflix son buenísimos en devops. Netflix hace microservicios. Por lo tanto: si yo hago microservicios, seré buenísimo en devops.
Hay muchos casos en los que se ha hecho un gran esfuerzo en adoptar patrones de microservicios sin realmente comprender cómo los costes y los beneficios se aplican a las especificaciones del problema que se tiene entre manos.
Vamos a describir en detalle qué son los microservicios, por qué el patrón es tan atractivo, y también cuáles son los desafíos fundamentales que conllevan.
Terminaremos con un conjunto de preguntas que pueden servir para preguntarte a ti mismo cuando estás valorando si los microservicios son un patrón apropiado para ti. Las preguntas están al final del artículo.
¿Qué son los microservicios y por qué son tan populares?
Empecemos por lo básico. Así es cómo una hipotética plataforma para compartir vídeos puede estar implementada, primero en forma monolítica (una unidad grande única) y luego en forma de microservicios:
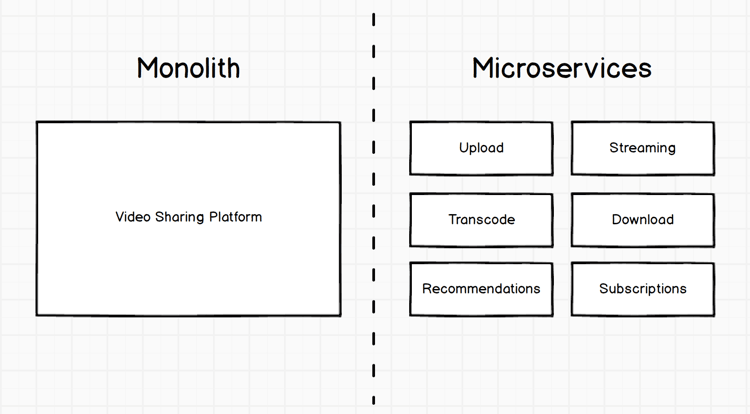
La diferencia entre los dos sistemas es que el primero es una unidad grande única: un monolito. La segunda es un conjunto de servicios pequeños y específicos. Cada servicio juega un papel concreto.
Cuando se dibuja este diagrama con este nivel de detalle, es fácil entender su atractivo. Hay un montón de ventajas potenciales:
-
Desarrollo Independiente: los componentes al ser pequeños e independientes, se pueden desarrollar por parte de pequeños equipos independientes. Un grupo de trabajo puede cambiar el servicio de 'Subir Vídeo' sin interferir en el servicio 'Transcodificar', o incluso sin saber que se están haciendo dichos cambios. La cantidad de tiempo que se necesita para aprender sobre un componente se reduce muchísimo, y es más fácil desarrollar nuevas funcionalidades.
-
Despliegue independiente: cada componente individual se puede implementar independientemente. Esto permite que las nuevas funciones se liberen con mayor velocidad y menos riesgo. Se pueden implementar correcciones o funciones para el componente 'Streaming' sin requerir que se desplieguen también otros componentes.
-
Escalabilidad independiente: cada componente se puede escalar independientemente el uno del otro. Durante las fechas con mucho tráfico cuando se liberan nuevos episodios, el componente 'Descarga' se puede escalar para manejar el aumento de carga, sin tener que escalar cada componente, lo que hace que el escalamiento elástico sea más factible y reduce los costes.
-
Reusabilidad: los componentes cumplen una función pequeña y específica. Esto significa que se pueden adaptar más fácilmente para su uso en otros sistemas, servicios o productos. El componente 'Transcodificar' podría ser utilizado por otras unidades de negocio, o incluso convertirse en un nuevo negocio, quizás ofreciendo servicios de transcodificación para otras empresas.
En este nivel de detalle, las ventajas de un modelo de microservicios sobre un modelo monolítico parecen obvias. Y si es así -¿por qué razón este patrón sólo se ha vuelto protagonista recientemente? ¿Dónde ha estado metido el resto de mi vida?
Si esto es tan genial, ¿por qué no se ha hecho antes?
Existen dos respuestas a esta pregunta. Una es que sí se ha hecho -dentro nuestras capacidades técnicas- , y la otra es que los avances técnicos más recientes nos han permitido llevarlo a un nuevo nivel.
Cuando comencé a escribir la respuesta a esta pregunta se me fue la mano y se convirtió en una descripción demasiado larga, así que realmente voy a separar parte de la explicación en otro artículo y publicarlo en el futuro. En esta entrada, voy a omitir el viaje de un solo programa a muchos programas, haré caso omiso de los ESBs (Buses de Servicio Empresarial), y de la arquitectura orientada a servicios (SOA), el diseño de componentes y contextos delimitados, y demás...
En cambio voy a decir que en muchos aspectos hemos estado haciendo esto desde hace bastante tiempo, pero con la reciente explosión en popularidad de la tecnología de contenedores (Docker en particular) y en la tecnología de orquestación (como Kubernetes, Mesos, Consul, etc...), este patrón se ha vuelto más viable a la hora de ser implementado desde un punto de vista técnico.
Así que, si damos por hecho que podemos implementar microservicios, tenemos que pensar cuidadosamente si debemos hacerlo. Ya hemos visto las ventajas teóricas, ¿pero cuáles son los retos de hacerlo?
¿Cuál es problema con los microservicios?
Si los microservicios son tan geniales, ¿qué es lo que pasa con ellos? Aquí van algunos de los problemas que he visto.
Mayor complejidad para los desarrolladores
Las cosas se ponen mucho más difíciles para los desarrolladores. En el caso de que un desarrollador quiera trabajar estando de viaje, o en una funcionalidad que pueda abarcar muchos servicios, ese desarrollador tiene que ejecutarlos todos en su máquina, o conectarse a ellos. Esto es a menudo más complejo que simplemente ejecutar un solo programa.
Este desafío se puede mitigar parcialmente con varias herramientas, pero a medida que aumenta el número de servicios que componen un sistema, mayor es el número de desafíos a los que se enfrentan los desarrolladores cuando se ejecuta el sistema en su conjunto.
Mayor complejidad para los operadores
Para los equipos que no desarrollan servicios, pero que los mantienen, se da una explosión en la complejidad potencial. En lugar de administrar algunos servicios en ejecución, están administrando docenas, cientos o miles de servicios en ejecución. Hay más servicios, más vías de comunicación y más áreas de potencial fracaso.
Mayor complejidad para devops
Leyendo los dos puntos anteriores, puede "chirriar" que las operaciones y el desarrollo sean tratados por separado hoy en día, especialmente dada la popularidad de DevOps como práctica (de la que soy un gran defensor). ¿No puede DevOps mitigar esto?
El desafío es que muchas organizaciones siguen funcionando con equipos de desarrollo y operaciones separados y, consecuentemente, las organizaciones que lo hacen son mucho más proclives a pasarlo mal con la adopción de microservicios.
Y para las organizaciones que sí han adoptado DevOps, sigue siendo difícil. Ser tanto desarrollador como operador ya es duro de por sí (a la vez que crítico para desarrollar un buen software), pero también lo es tener que entender los matices de los sistemas de orquestación de contenedores, especialmente sistemas que están evolucionando a un ritmo rápido, es muy difícil. Lo que me lleva al siguiente punto.
Requiere un nivel de pericia muy alto
Cuando lo hacen los expertos, los resultados pueden ser maravillosos. Pero imagínate una organización en la que las cosas no están funcionando del todo bien con un único sistema monolítico. ¿Qué razón habría para argumentar que las cosas irían mejor aumentando el número de sistemas, lo que a su vez aumenta la complejidad operativa?
Sí, con una automatización eficaz, monitorización, orquestación y demás, todo esto es posible. Pero la dificultad raramente está en la tecnología: el desafío es encontrar personas que puedan usarla de manera efectiva. Estas habilidades están actualmente muy demandas, y va a ser difícil encontrar personas capacitadas para hacerlo bien.
Los sistemas del mundo real están muy mal delimitados
En todos los ejemplos que se utilizan para describir las ventajas de los microservicios, se habla de componentes independientes. Sin embargo, en muchos casos los componentes simplemente no son independientes. Sobre el papel, ciertos dominios pueden parecer bien delimitados, pero a medida que se rasca en la superficie y se entra en detalle, puedes encontrar que son más difíciles de modelar de lo que se esperaba.
Aquí es donde las cosas pueden llegar a ponerse extremadamente complejas. Si en realidad sus límites no están bien definidos, entonces lo que sucede es que, aunque teóricamente los servicios se pueden implementar de forma aislada, te encuentras que debido a las interdependencias entre ellos, debes implementar conjuntos de servicios como un grupo, y no de forma independiente.
Esto significa que es necesario administrar versiones coherentes de los servicios probados y testados cuando trabajan juntos, y en realidad dispones de un sistema de despliegue independiente, ya que para implementar una nueva función, es necesario orquestar con cuidado el despliegue simultáneo de muchos servicios.
Se obvian con frecuencia las complejidades de estado
En el ejemplo anterior he mencionado que la implementación de funcionalidades puede requerir el despliegue simultáneo de varias versiones de varios servicios en tándem. Es tentador asumir que una estrategia basada en técnicas de despliegue e implementación sensatas puede llegar a mitigar esto: por ejemplo despliegues azules/verdes (que la mayoría de las plataformas de orquestación de servicios gestionan con poco esfuerzo), o múltiples versiones de un servicio ejecutándose en paralelo, con los canales que los consumen decidiendo qué versión utilizar.
Estas técnicas mitigan un gran número de desafíos si los servicios no tienen estado. Pero los servicios sin estado son, francamente, fáciles de gestionar. De hecho, si tienes servicios sin estado, entonces me inclinaría por obviar los microservicios en su conjunto y considerar el uso de un modelo de arquitectura sin servidor.
En realidad, muchos servicios requieren estado. Un ejemplo en nuestra hipotética plataforma para compartir vídeos podría ser el servicio de suscripción. Una nueva versión del servicio de suscripciones podría almacenar datos en la base de datos de suscripciones de forma diferente. Si estás ejecutando ambos servicios en paralelo, estás ejecutando el sistema con dos esquemas a la vez. Si realizas una implementación verde/azul y otros servicios dependen de los datos de la nueva forma, entonces deben actualizarse al mismo tiempo, y si la implementación del servicio de suscripción falla y retrocede (hace un rollback), es posible que necesiten retroceder también los otros servicios, con consecuencias en cascada.
De nuevo, puede ser tentador pensar que con bases de datos NoSQL estos problemas de esquema desaparecen, pero no es así. Las bases de datos que no imponen el esquema no conducen a sistemas de BBDD sin esquema, sólo significa que el esquema tiende a ser administrado en el nivel de la aplicación, en lugar del nivel de la base de datos. La dificultad fundamental de entender la forma de sus datos, y cómo evolucionan, no se puede evitar...
A medida que se construye una gran red de servicios que dependen unos de otros, es muy probable que haya mucha comunicación entre los servicios. Esto implica nuevos retos. En primer lugar, hay muchos más puntos en los que las cosas pueden fallar. Debemos contar con que las llamadas de red van a fallar, lo que significa que cuando un servicio llama a otro, debe tener en cuenta que va a tener que reintentarlo un número de veces como mínimo. Ahora, cuando un servicio tiene que potencialmente llamar a muchos servicios, terminamos teniendo entre manos una situación muy complicada.
Supón que un usuario sube un vídeo al servicio de compartir vídeos. Quizás tengamos que ejecutar el servicio de subir vídeo, pasar datos al servicio de transcodificar, actualizar las suscripciones, actualizar las recomendaciones y demás. Todas estas llamadas requieren un grado de orquestación, y si las cosas fallan necesitamos reintentarlo.
Esta lógica del reintento se puede volver complicada de gestionar. Intentar hacer las cosas de manera sincronizada a menudo termina siendo insostenible, ya que hay muchos puntos en los que las cosas pueden ir mal. En estos casos, una solución más fiable es usar patrones asíncronos para gestionar la comunicación. El reto aquí es que los patrones asíncronos inherentemente hacen que el sistema tenga estado. Como hemos dicho en el punto anterior, los sistemas con estados y los sistemas con estados distribuidos son muy difíciles de gestionar.
Cuando un sistema de microservicios usa colas de mensajes para la comunicación dentro del servicio, lo que tienes básicamente es una gran base de datos (lo cola de mensajes o broker) que mantiene la adhesión entre los servicios. Nuevamente, aunque no parezca mucho lío de antemano, el esquema volverá a ti para explotarte en las manos. Un servicio en la versión X quizás escriba un mensaje con un formato determinado, los servicios que dependan de este mensaje también tendrán que ser actualizados cuando el servicio de envío cambie los detalles del mensaje que envía.
Sí, es posible tener servicios que puedan manejar mensajes en muchos formatos diferentes, pero esto es difícil de gestionar. Ahora, cuando se implementan nuevas versiones de servicios, hay momentos en que dos versiones diferentes de un servicio pueden estar intentando procesar mensajes desde la misma cola, quizás incluso mensajes enviados por diferentes versiones de un servicio de envío. Esto puede llevar a casuísticas complicadas incontrolables. Para evitar estas casuísticas raras, quizás sea más fácil permitir que solo existan ciertas versiones de los mensajes, lo que significa que es necesario implementar un conjunto de versiones de un conjunto de servicios como un todo coherente, asegurando que los mensajes de versiones anteriores se drenen correctamente antes.
Esto resalta de nuevo la idea de que los despliegues independientes pueden no tener el resultado esperado cuando entras a ver los detalles.
Versionar se vuelve complicado
Para mitigar las dificultades mencionadas anteriormente, las versiones deben ser gestionadas con mucho cuidado. Una vez más, puedes tender a asumir que siguiendo un estándar como SemVer se resolverá el problema. No es así. SemVer es una convención sensata que puedes usar, pero aún tendrás que hacer un seguimiento de las versiones de los servicios y de las APIs que pueden trabajar junto a ellos.
La gestión de dependencias en sistemas de software es notoriamente difícil, ya sean módulos de Node.js, módulos Java, bibliotecas C o lo que sea. Los problemas que surgen de los conflictos entre componentes independientes cuando son consumidos por una sola entidad son muy difíciles de resolver.
Estos escollos son complicados de gestionar cuando las dependencias son estáticas, y pueden ser parcheadas, actualizadas, editadas y así sucesivamente, pero si las dependencias son ellas mismas servicios en vivo, entonces probablemente no puedas simplemente actualizarlos: es posible que tengas que ejecutar muchas versiones (con la dificultad que ello conlleva y que ya hemos descrito) o tirar abajo el sistema hasta que lo puedas arreglar del todo.
Transacciones distribuidas
En las situaciones en las que necesitas la integridad de la transacción a lo largo de una operación, los microservicios se pueden convertir en un dolor de muelas. Los estados distribuidos son difíciles de manejar, hay muchas pequeñas unidades que pueden fallar y hacen que la orquestación de transacciones sea muy complicada.
Puede ser muy tentador intentar evitar el problema haciendo que las operaciones sean idempotentes (aquellas que el efecto de ejecutarlas más de una vez es el mismo), ofreciendo mecanismos de reintento y demás, y en muchos casos esto puede funcionar. Pero quizás se den escenarios en los que simplemente necesites que una transacción falle o tenga éxito, y nunca quedarse en un estado intermedio. El esfuerzo que implica trabajar para sortear esto o para implementarlo en un modelo de microservicios puede ser demasiado grande.
Los microservicios pueden llegar a ser monolitos disfrazados
Sí, los servicios y componentes individuales pueden implementarse de forma aislada, sin embargo en la mayoría de los casos vas a tener que ejecutar algún tipo de plataforma de orquestación, como Kubernetes. Si estás utilizando un servicio gestionado, como GKE de Google, EKS de Amazon o AKS de Azure, entonces una gran parte de la complejidad de administrar el clúster lo gestionan por ti.
Sin embargo, si estás administrando el clúster por tu cuenta, estás gestionando un sistema grande, complicado, de misión crítica. Aunque los servicios individuales pueden ofrecer todas las ventajas descritas anteriormente, es necesario administrar con mucho cuidado el clúster. Las implementaciones de este sistema pueden ser complejas, las actualizaciones pueden ser difíciles, la puesta en marcha de medidas de failover en caso de error puede resultar muy complicada y así sucesivamente...
En muchos casos los beneficios globales están ahí, pero es importante no trivializar o subestimar la complejidad adicional de administrar otro sistema grande y complejo. Los servicios gestionados pueden ayudar, pero en muchos casos estos servicios son recién nacidos y no están aún maduros (Amazon EKS fue anunciado tan sólo a finales de 2017 por ejemplo).
¡El fin de la locura de los microservicios!
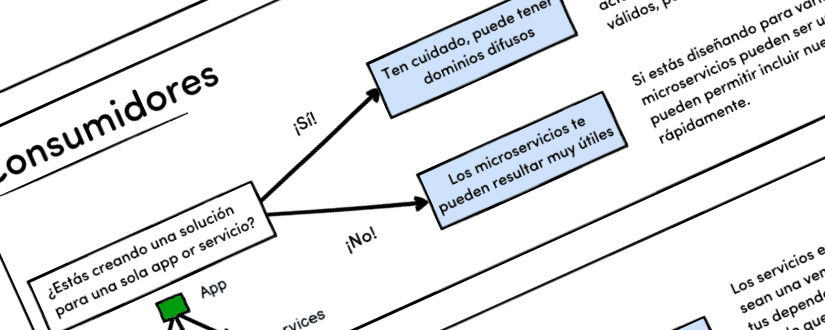
Evita caer en la locura tomando decisiones ponderadas cuidadosamente. Para ayudarte en este aspecto he elaborado una serie de preguntas y respuestas que te permitirán tomar una mejor decisión:
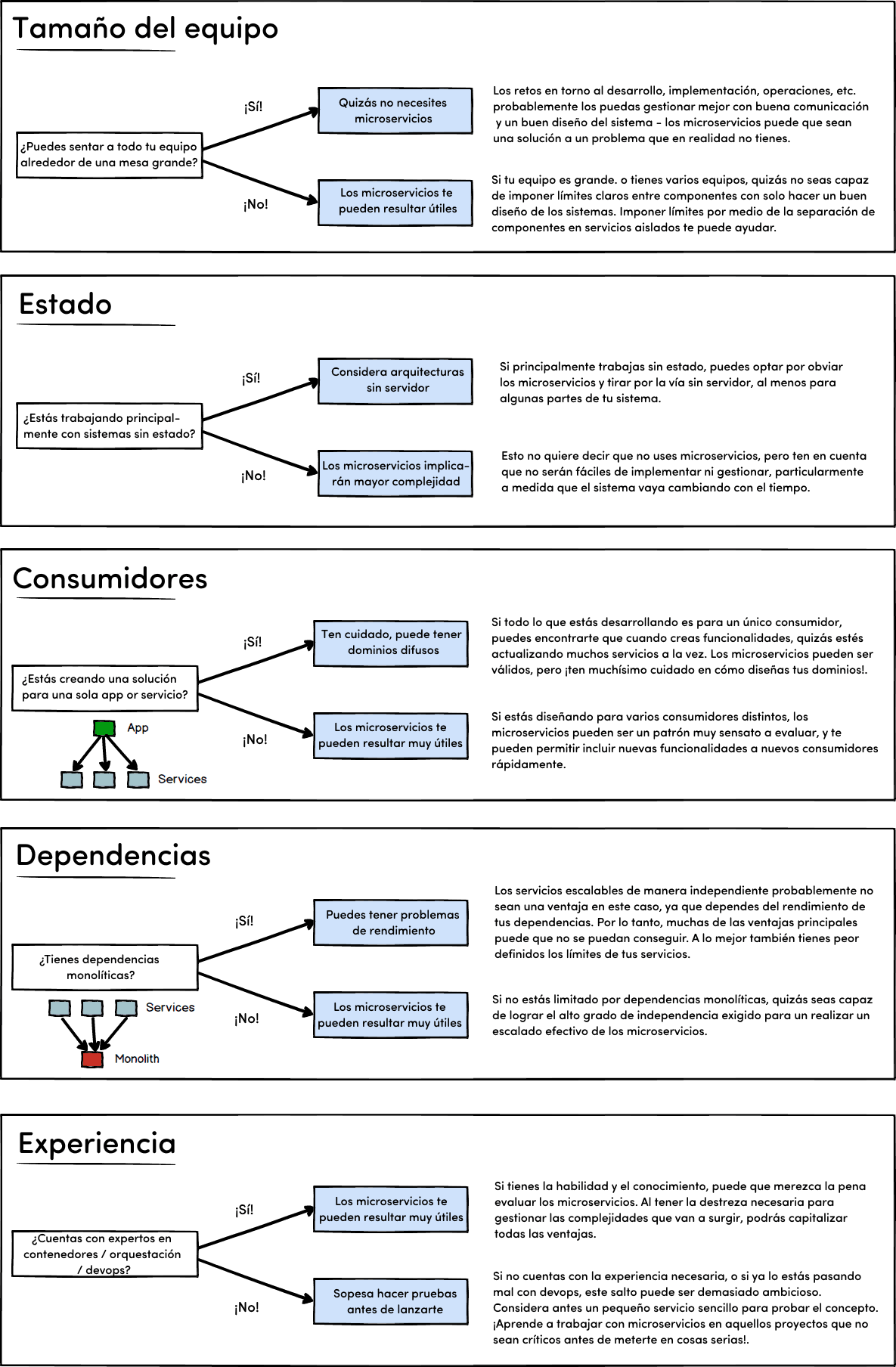
Puedes descargar una copia en PDF aquí: Consideraciones-Microservicios.pdf
Un último apunte: no confundas microservicios con arquitectura
He evitado esa palabra que empieza por 'a' de forma deliberada. Pero mi amigo Zoltan me hizo un buen apunte al revisar este artículo (al cual también ha contribuido).
No existe la arquitectura de microservicios. Los microservicios son simplemente otro patrón o implementación de componentes, nada más, nada menos. Si están presentes en un sistema o no, no significa que la arquitectura del sistema esté resuelta.
Los microservicios se relacionan de muchas maneras con los procesos técnicos en torno al empaquetado y las operaciones, y no con el diseño intrínseco del sistema. Los límites apropiados de los componentes continúan siendo uno de los retos más importantes a la hora de hacer ingeniería de sistemas.
Independientemente del tamaño de tus servicios, ya estén en contenedores Docker o no, siempre tendrás que pensar cuidadosamente sobre cómo montar un sistema. No hay una respuesta válida, y hay un montón de opciones.
¡Espero que te haya resultado útil este artículo! Como siempre, por favor comenta debajo si tienes cualquiera pregunta o si quieres aportar algo a lo expuesto aquí.
También puedes seguir algunas animadas discusiones sobre el artículo en:
Apéndice: Lecturas adicionales
Los siguientes enlaces puede que te resulten de utilidad (todos en inglés):
Por favor, ¡comparte cualquier otro recurso que creas que sea una buena lectura o visionado sobre el tema!