El Structured Query Language o SQL es el lenguaje utilizado por la mayoría de los Sistemas Gestores de Bases de Datos Relacionales (SGBDR) surgidos a finales de los años 70, y que llega hasta nuestros días. Es, sin duda, la mejor inversión en aprendizaje que puedes hacer, incluso aunque no te dediques a programación. En esta serie de tutoriales te vamos a enseñar a utilizarle y a sacarle partido.
 El Structured Query Language o SQL es el lenguaje utilizado por la mayoría de los Sistemas Gestores de Bases de Datos Relacionales (SGBDR) surgidos a finales de los años 70, y que llega hasta nuestros días.
El Structured Query Language o SQL es el lenguaje utilizado por la mayoría de los Sistemas Gestores de Bases de Datos Relacionales (SGBDR) surgidos a finales de los años 70, y que llega hasta nuestros días.
Es una reiteración hablar de “Lenguaje SQL”, ya que lo de “lenguaje” va incluido en el nombre, aunque lo cierto es que casi todo el mundo lo dice así.
En 1986 fue estandarizado por el organismo ANSI (American nacional Standard Institute), dando lugar a la primera versión estándar de este lenguaje, el SQL-86 o SQL1. Al año siguiente este estándar es adoptado también por el organismo internacional ISO (International Standarization Organization).
La parte fundamental de SQL es un estándar internacional.
A lo largo del tiempo se ha ido ampliando y mejorando. En la actualidad SQL es el estándar de facto de la inmensa mayoría de los SGBDR comerciales. El soporte del estándar es general y muy amplio, pero cada sistema (Oracle, SQL Server, MySQL...) incluye sus ampliaciones y pequeñas particularidades.
El ANSI SQL ha ido sufriendo varias revisiones a lo largo del tiempo, a continuación vienen indicadas en la siguiente tabla:
| Año |
Nombre |
Alias |
Comentarios |
| 1986 |
SQL-86 |
SQL-87 |
Primera versión estándar de ANSI |
| 1989 |
SQL-89 |
FIPS 127-1 |
Revisión menor. Añade restricciones de integridad. |
| 1992 |
SQL-92 |
SQL2, FIPS 127-2 |
Actualización grande equivalente a ISO 9075 |
| 1999 |
SQL:1999 |
SQL3 |
Se añaden coincidencias mediante expresiones regulares, consultas recursivas, clausuras transitivas, disparadores, estructuras de control de flujo, tipos no escalares y algunas características de orientación a objetos. |
| 2003 |
SQL:2003 |
SQL 2003 |
Se añaden características relacionadas con XML (la moda de la época), secuencias estandarizadas, y campos con valores auto-generados (incluyendo columnas de identidad). |
| 2006 |
SQL:2006 |
SQL 2006 |
La ISO/IEC 9075-14:2006 define formas en las que SQL se puede utilizar con XML (importar y almacenar XML, manipularlo directamente en la base de datos...). Muy centrada en este aspecto concreto. |
| 2008 |
SQL:2008 |
SQL 2008 |
Permite la cláusula ORDER BY fuera de las definiciones de cursores. Añade disparadores de tipo INSTEAD OF. Añade la cláusula TRUNCATE. |
| 2011 |
SQL:2011 |
SQL 2011 |
Añade características de manejo de datos temporales, así como tablas versionadas en el sistema, etc... |
| 2016 |
SQL:2016 |
SQL 2016 |
Añade coincidencia de patrones por filas, funciones de tabla polimórficas y JSON. |
| 2019 |
SQL:2019 |
SQL 2019 |
Añade arrays multi-dimensionales. |
El lenguaje SQL se divide en tres subconjuntos de instrucciones, según la funcionalidad de éstas:
- DML (Data Manipulation Language – Lenguaje de Manipulación de Datos): se encarga de la manipulación de los datos. Es lo que usamos de manera más habitual para consultar, generar o actualizar información.
- DDL (Data Definition Language – Lenguaje de Definición de Datos): se encarga de la manipulación de los objetos de la base de datos, por ejemplo, crear tablas u otros objetos.
- DCL (Data Control Language – Lenguaje de Control de Datos): se encarga de controlar el acceso a los objetos y a los datos, para que los datos sean consistentes y sólo puedan ser accedidos por quien esté autorizado a ello.
El modelo relacional
El diseño de una base de datos consiste en definir la estructura que deben tener los datos en un sistema de información determinado. Para ello se suelen seguir por regla general unas fases en el proceso de diseño, definiendo para ello el modelo conceptual, el lógico y el físico.
No vamos a entrar en ello en este tutorial, pero sí veremos lo más fundamental para alcanzar nuestro objetivo: realizar consultas sobre los datos.
Si quieres arañar un poco más la superficie de este tema del diseño de bases de datos puedes leer nuestro artículo: Diseñando una base de datos en el modelo relacional.
En el modelo relacional, el diseño de la base de datos se implementa mediante lo que se conoce como diagramas de Entidad/Relación (que es el modelo conceptual de los datos). Éste se plasma en tablas y relaciones entre éstas (el llamado modelo lógico).
Este modelo relacional de bases de datos se rige por algunas normas sencillas:
- Todos los datos se representan en forma de tablas (también llamadas "relaciones"). Incluso los resultados de consultar otras tablas. La tabla es además la unidad de almacenamiento principal.
- Las tablas están compuestas por filas (o registros) y columnas (o campos), que almacenan la información sobre una entidad de datos concreta, y se consideran una unidad.
- Cada tabla debe poseer una clave primaria, esto es, un identificador único de cada registro compuesto por una o más columnas.
- Para establecer una relación entre dos tablas es necesario incluir, en forma de columna, en una de ellas la clave primaria de la otra. A esta columna se le llama clave externa.
Basándose en estos principios se diseñan las diferentes bases de datos relacionales, definiendo un diseño conceptual, que luego se implementa en el diseño físico usando para ello el gestor de bases de datos de nuestra elección.
La base de datos de ejemplo, Northwind
En este tutorial vamos a trabajar con una conocida base de datos creada por Microsoft hace muchos años como ejemplo para hacer consultas con su base de datos de escritorio llamada Access. Se trata de Northwind.

Esta base de datos modela de manera sencilla la actividad de una empresa ficticia de venta de productos alimentarios llamada "Northwind Traders". Aunque se trata de una base de datos sencilla, tiene información de todo tipo, suficiente para nuestro objetivo de aprender a realizar consultas básicas: clientes, proveedores, productos, pedidos, transportistas, empleados...
Su esquema de tablas y relaciones entre ellas es el que se puede ver a continuación:
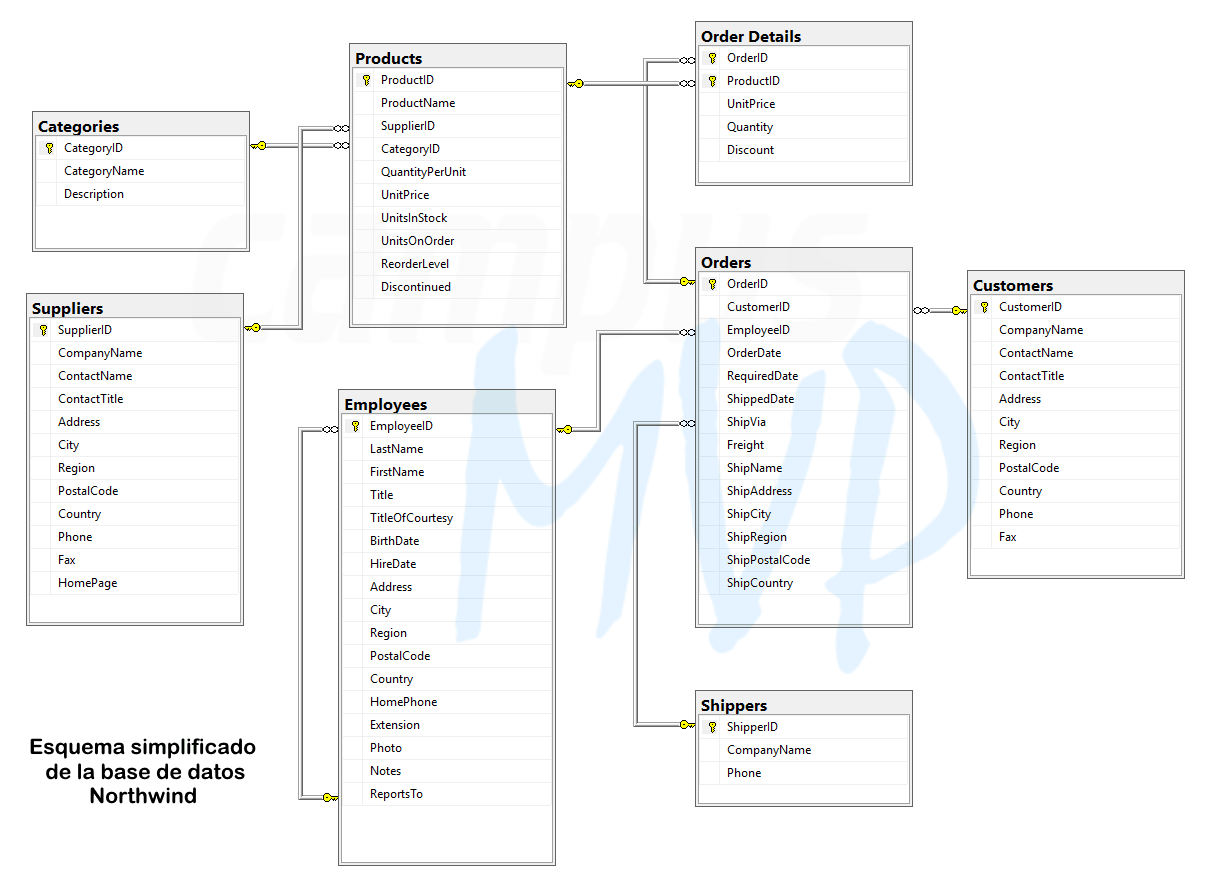
Como vemos existen tablas para representar cada una de estas entidades del mundo real: Proveedores (Suppliers), Productos, Categorías de productos, Empleados, Clientes, Transportistas (Shippers), y Pedidos (Orders) con sus correspondientes líneas de detalle (OrderDetails).
Además están relacionadas entre ellas de modo que, por ejemplo, un producto pertenece a una determinada categoría (se relacionan por el campo CategoryID) y un proveedor (SupplierID), y lo mismo con las demás tablas. Esto se representa visualmente por medio de las flechas con una llave en el extremo que ves en el diagrama anterior.
Cada tabla posee una serie de campos que representan valores que queremos almacenar para cada entidad. Por ejemplo, un producto posee los siguientes atributos que se traducen en los campos correspondientes para almacenar su información: Nombre (ProductName), Proveedor (SupplierID, que identifica al proveedor), Categoría a la que pertenece (CategoryID), Cantidad de producto por cada unidad a la venta (QuantityPerUnit), Precio unitario (UnitPrice), Unidades que quedan en stock (UnitsInStock), Unidades de ese producto que están actualmente en pedidos (UnitsOnOrder), qué cantidad debe haber para que se vuelva a solicitar más producto al proveedor (ReorderLevel) y si está descatalogado o no (Discontinued).
Los campos marcados con una llave de color amarillo (por ejemplo CategoryID o ProductID) indican aquellos que son claves primarias (o "PK"), es decir, que identifican de manera única a cada entidad. Por ejemplo, ProductID es el identificador único de cada producto, que será por regla general un número entero que se va incrementando cada vez que introducimos un nuevo producto (1, 2, 3, etc..). Ya aprenderás la importancia de disponer de este campo.
Otros campos almacenan claves primarias de otras tablas de modo que se puedan relacionar con la tabla actual. Es lo que se denominan claves foráneas o claves externas (también llamadas simplemente "FK"). Por ejemplo, en la tabla de productos el campo CategoryID, porque en él se guardará el identificador único de la categoría asociada al producto actual o SupplierID porque almacena la clave primaria para identificar al proveedor del producto.
La herramienta que utilizaremos

Existen infinidad de herramientas gestoras de base de datos en el mercado pensadas para todas las necesidades. Seguro que te suena el nombre de muchas de las más conocidas: SQL Server, MySQL, Oracle, MariaDB, PostgreSQL...
La mayor parte de ellas ofrecen una versión gratuita o directamente son de código abierto. Pero todas tienen sus particularidades y es necesario instalarlas y configurarlas, cargar los datos de prueba... lo cual puede hacer que se complique la cosa.
Por ello, y para simplificar el aprendizaje del lenguaje SQL estándar (que luego te servirá con cualquiera de ellas), hemos optado por utilizar un conocido sistema de bases de datos que te simplificará mucho la tarea: SQLite. De hecho, para utilizarlo con facilidad haremos uso de la herramienta SQLite Browser, que nos ofrece una interfaz de usuario para gestionar y consultar las bases de datos SQLite.
Esto nos proporciona muchas ventajas:
- Aunque lo más fácil es instalarlo, puedes simplemente descargar un ZIP, descomprimirlo y estar funcionando en un minuto.
- Funciona en todos los sistemas operativos: Windows, macOS, Linux... e incluso en móviles, etc... aunque para el curso usaremos siempre el escritorio.
- Es muy pequeño y ligero por lo que podrás usarlo aunque tu ordenador sea muy viejo.
- Además es muy compatible con el estándar SQL. Todo lo que aprendas te va a valer para luego usarlo con cualquier otro gestor de datos.
IMPORTANTE: para poder seguir este tutorial en sus próximas etapas, asegúrate de ver el vídeo del principio en el que se explica cómo poner en marcha el entorno para practicar. Debes descargar SQLite Browser así como la base de datos de ejemplo Northwind.
---
A lo largo de las próximas entregas iremos aprendiendo las partes más importantes de este lenguaje, fundamental para la práctica totalidad de los programadores, sea cual sea su trabajo.