En un anterior artículo presentábamos Docker Swarm Mode y lo comparábamos con Kubernetes para que conocieses sus similitudes y diferencias, así como sus ventajas e inconvenientes. Ahora vamos a ver cómo usarlo en la práctica añadiendo contenedores e instancias a un "enjambre" y montando enjambres con múltiples contenedores y servicios.

En un anterior artículo presentábamos Docker Swarm Mode y lo comparábamos con Kubernetes para que conocieses sus similitudes y diferencias, así como sus ventajas e inconvenientes.
Ahora vamos a ver cómo usarlo en la práctica. Parto de la base de que te suena la terminología básica de Docker y Kubernetes.
Crear un clúster con Docker Swarm Mode
Vamos a ver la manera de crear un clúster de Swarm. Para ello crearemos un clúster en local con un solo nodo (nuestra máquina). En Swarm un nodo puede ser master y worker a la vez. Esto sería lo más parecido a MiniKube en términos de Swarm (sin necesidad de máquina virtual).
No necesitas descargarte nada especial, la propia CLI de Docker te sirve:
docker swarm init --advertise-addr a.b.c.d
El parámetro --advertise-addr es la IP de tu máquina (no uses localhost, usa la IP que tengas como p. ej. 192.168.0.3). En Docker for Windows o for Mac no es necesario, pero, a veces, se queja de que no puede encontrar la IP. Si es el caso, ponlo y ya está. La salida será algo como:
Swarm initialized: current node (vv5cj2x80hl0gf5hphjum6lnh) is now a manager.
To add a worker to this swarm, run the following command:
docker swarm join --token SWMTKN-1-68p2up61o0kni0g3rr3vhwbucezwcyes4um9pkmm34z1ahpfmt-0cnt15yyzollvhlrb5r3e1x6w 10.6.1.3:2377
To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
Esto nos indica que la máquina es ahora un nodo manager del clúster Swarm, y nos proporciona el comando necesario para añadir workers y managers al mismo (repasa el artículo anterior para conocer esta terminología si no la tienes clara).
En nuestro caso, para el ejemplo, no vamos a añadir ninguno, pero si tuvieses cualquier otra máquina con Docker instalado podrías agregarla al clúster de máquinas que van a ejecutar contenedores con Swarm.
Cuando se inicializa un clúster, Swarm crea dos tokens: uno sirve para añadir workers y otro para añadir managers. En función del token que se pase a docker swarm join la máquina afectada se unirá como manager o como worker.
Puedes ver esos tokens con docker swarm join-token [worker|manager]. De hecho, la salida de este comando no es solo el token, sino todo el comando docker swarm join que debes lanzar:

Te lo muestro en la práctica en este vídeo:
Desplegar un hello world
Bueno, vamos a empezar por algo fácil. Vamos a desplegar un hello world en Swarm. Para ello debes hacer lo siguiente:
- Crear un fichero
docker-compose.yml que defina un servicio llamado hello-swarm. Este servicio debe usar la imagen dockercampusmvp/go-hello-world:latest (está en Docker Hub con ese nombre y etiqueta), y tener su puerto 80 mapeado al 8000 del host.
- Una vez lo hayas creado (si tienes cualquier problema te lo puedes descargar ya hecho desde aquí), desde la carpeta donde tengas este fichero Compose teclea:
docker stack deploy -c docker-compose.yml helloswarm
Acabas de desplegar la aplicación helloswarm (usando el fichero Compose especificado). En la terminología Swarm llamamos stacks a las aplicaciones. La salida será algo parecido a:
Creating network helloswarm_default
Creating service helloswarm_hello-swarm
Vamos a verificar que el servicio está en marcha. Para ello debemos usar docker stack services <nombre-app>. Es decir, en este caso usaremos docker stack services helloswarm:
ID NAME MODE REPLICAS IMAGE PORTS
41c151cruk8i helloswarm_hello-swarm replicated 1/1 dockercampusmvp/go-hello-world:latest *:8000->80/tcp
La columna REPLICAS nos indica que se está ejecutando una réplica del servicio (del total de una que habíamos solicitado). De hecho, si haces docker ps deberías ver el contenedor ejecutándose. Si ahora lo pruebas (navegando a localhost:8000) te debería responder:

Nota: podríamos haber usado también docker service ls que devuelve todos los servicios (no solo los de la aplicación indicada).
Escalando el servicio
Vamos a escalar el servicio. Para ello usamos el comando docker service scale:
docker service scale helloswarm_hello-swarm=10
Observa que el nombre del servicio está formado por el nombre de la aplicación (helloswarm), un guion bajo (subrayado) y el nombre del servicio declarado en el fichero Compose. Al cabo de un rato la salida será como la que muestra la imagen:
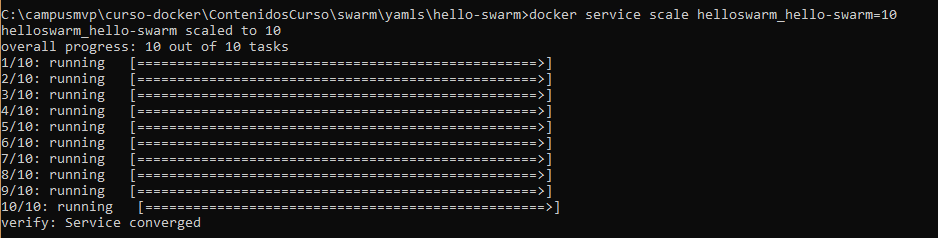
Si ejecutas un docker ps deberías ver los 10 contenedores en marcha:

Y un docker service ls te debería mostrar el servicio con las 10 instancias.
¡Fantástico! Ahora si llamas con http://localhost:8000 te irán respondiendo distintas instancias cada vez:
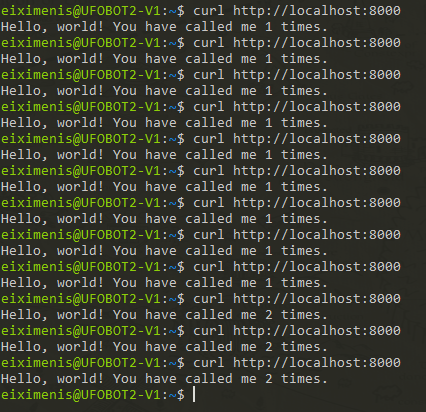
Escalado usando el fichero YAML
También se puede escalar usando el fichero YAML. Para ello usamos la propiedad deploy.replicas:
version: '3'
services:
my-svc:
image: my-image
deploy:
replicas: 10
Este fichero YAML escala el servicio para que tenga 10 réplicas.
Desplegar en Swarm una aplicación multicontenedor
En el siguiente vídeo te muestro cómo puedes hacer lo anterior, pero con múltiples contenedores diferentes.
Los archivos .yml utilizados los tienes aquí.
En resumen
En estos dos artículos y vídeos hemos estudiado qué es Swarm y cómo se compara con Kubernetes. También hemos estudiado cómo crear clústeres de Swarm y la forma de desplegar aplicaciones (workloads) en ellos.
Como has visto, todo lo que ya sabes de Compose se reaprovecha para Swarm, así que, hacer uso de Swarm es realmente muy fácil.
La principal ventaja es que tanto la creación del clúster como el despliegue de aplicaciones es muy sencillo comparado con otras soluciones como Kubernetes: se utiliza la misma CLI y los mismos conceptos para todo y, además, solo mantenemos un conjunto de ficheros: los ficheros de Compose.
De todos modos, como se dijo en el artículo anterior, la industria se ha decantado por Kubernetes. No hay una sola razón para ello, sino una combinación de varios factores, entre los que podríamos listar:
- Swarm es muy propietario de Docker, mientras que Kubernetes es más abierto y pertenece a la CNCF (Cloud Native Computing Foundation).
- Kubernetes es un proyecto más maduro y más potente que Swarm. A pesar de que Swarm ha mejorado (a medida que Compose lo hacía), el estar atado al formato de Compose le termina penalizando. Muchas empresas empezaron con Kubernetes porque Swarm no les ofrecía un modelo lo suficientemente potente y una vez pagado el precio de "conocer Kubernetes" y su modelo de despliegue, ya no tiene mucho sentido volver atrás. Esto ha ejercido un efecto de arrastre: quien entra en el mundo de los orquestadores actualmente, probablemente lo hará en Kubernetes.
- La irrupción de Kubernetes "manejados" en el cloud también es importante. Una de las principales trabas de Kubernetes es desplegarlo y mantenerlo on premises. Actualmente, todos los grandes proveedores de cloud (Amazon, Google, Microsoft, IBM) ofrecen Kubernetes manejados, de forma que nos olvidamos de instalar y actualizar el clúster. En un mundo que se está moviendo al cloud, la facilidad de instalación de Swarm deja de ser algo relevante cuando cualquiera puede tener un clúster de Kubernetes en unos pocos minutos sin necesidad de conocer nada acerca de cómo se instala. Tanto es así, que la propia Docker ha integrado Kubernetes (en Docker Desktop y en Docker Engine).
Si quieres aprender Docker y Kubernetes a fondo, aquí tienes el recurso que necesitas.