
Casi cualquier aplicación que vayamos a construir, tarde o temprano tiene que lidiar con la persistencia de sus datos. Es decir, debemos lograr que los datos que maneja o genera la aplicación se almacenen fuera de esta para su uso posterior.
Esto, por regla general, implica el uso de un sistema de base de datos, bien tradicional basado en SQL, bien de tipo documental (también conocido como No-SQL).
A la hora de desarrollar, los programas modernos modelan su información utilizando objetos (Programación Orientada a Objetos), pero las bases de datos utilizan otros paradigmas: las relaciones (también llamadas a veces "Tablas") y las claves externas que las relacionan. Esta diferencia entre la forma de programar y la forma de almacenar da lugar a lo que se llama "desfase de impedancia" y complica la persistencia de los objetos.
Para minimizar ese desfase del que hablo y facilitar a los programadores la persistencia de sus objetos de manera transparente, nacen los denominados ORMs o mapeadores Objeto-Relacionales.
¿Qué es JPA?
Ahora que ya estamos más o menos situados, podemos empezar a ver qué es la API de Persistencia de Java o JPA.
Nota: aunque API de persistencia era su nombre original y, en realidad, el que todo el mundo sigue usando, conviene saber que el nombre oficial ahora es Jakarta Persistence, ya que Jakarta es el nombre actual de lo que antiguamente se llamaba Java Platform Enterprise Edition o Java EE (también llamada coloquialmente "Java empresarial"). El motivo es que en 2018 pasó a gestionarlo la fundación Eclipse y, como Java es una marca registrada de Oracle, se vieron forzados también a cambiarle el nombre, decidiéndose por "Jakarta".
JPA es una especificación que indica cómo se debe realizar la persistencia (almacenamiento) de los objetos en programas Java. Fíjate en que destaco la palabra "Especificación" porque JPA no tiene una implementación concreta, sino que, como veremos enseguida, existen diversas tecnologías que implementan JPA para darle concreción.
JPA forma parte de Java empresarial desde su versión 5, en el año 2006. Desde entonces han aparecido varias versiones de la especificación, que sigue el proceso de la comunidad Java, siendo la más reciente la 2.2, aparecida en el verano de 2017.
Aunque forma parte de Java empresarial, las implementaciones de JPA se pueden emplear en cualquier tipo de aplicación aislada, sin necesidad de usar ningún servidor de aplicaciones, como una mera biblioteca de acceso a datos.
¿Cómo funciona JPA?
Dado que es una especificación, JPA no proporciona clase alguna para poder trabajar con la información. Lo que hace es proveernos de una serie de interfaces que podemos utilizar para implementar la capa de persistencia de nuestra aplicación, apoyándonos en alguna implementación concreta de JPA.
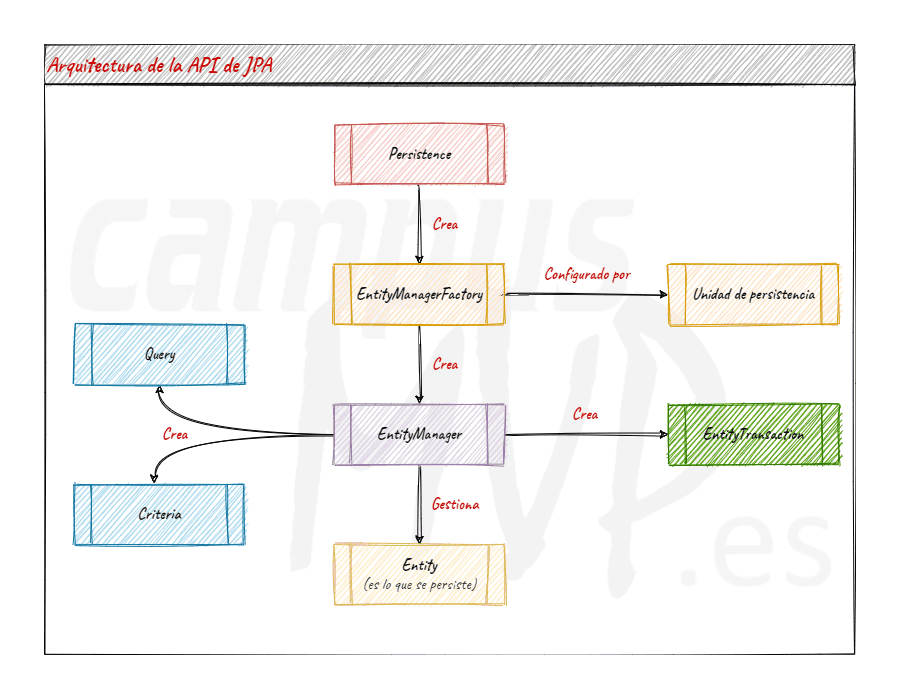
Es decir, en la práctica significa que lo que vas a utilizar es una biblioteca de persistencia que implemente JPA, no JPA directamente. Más adelante, veremos algunas de estas implementaciones, pero, mientras tanto, conviene saber qué funcionalidades definen estas interfaces en la especificación, mediante las interfaces del diagrama anterior, ya que luego serán las que utilices con cada implementación concreta.
1.- Mapeado de entidades
Lo primero que tienes que hacer para usar una implementación de JPA es añadirla al proyecto y configurar el sistema de persistencia (por ejemplo, la cadena de conexión a una base de datos). Pero, tras esas cuestiones de "fontanería", lo más básico que deberás hacer y que es el núcleo de la especificación es el mapeado de entidades.
El "mapeado" se refiere a definir cómo se relacionan las clases de tu aplicación con los elementos de tu sistema de almacenamiento.
Si consideramos el caso común de acceso a una base de datos relacional, sería definir:
- La relación existente entre las clases de tu aplicación y las tablas de tu base de datos
- La relación entre las propiedades de las clases y los campos de las tablas
- La relación entre diferentes clases y las claves externas de las tablas de la base de datos
Esto último es muy importante, ya que permite definir propiedades en tus clases que son otras clases de la aplicación, y obtenerlas automáticamente desde la persistencia en función de su relación. Mejor veámoslo con un ejemplo:
@Entity
public class Factura {
@ManyToOne
private List<LineaFactura> lineasFactura;
...
}
En este ejemplo, cada factura consta de varias líneas de factura, y con estos atributos estamos definiendo esta circunstancia. Posteriormente, cuando obtengamos una factura podremos consultar sus líneas de factura de manera transparente, pues será la implementación concreta de JPA la que se encargue de obtener automáticamente las asociadas a esa factura desde la base de datos sabiendo de esta relación.
Como ves, esto facilita enormemente el acceso a datos, y creo que ahora le empezarás a ver la potencia a JPA.
Nota: aunque esto es muy cómodo, es necesario tener mucho cuidado con los tipos de relaciones que definimos y de qué manera y dónde lo hacemos, ya que puede influir negativamente en el rendimiento de nuestra aplicación.
Como puedes observar en el fragmento anterior, lo que define JPA es también una serie de anotaciones con las que podemos decorar nuestras clases, propiedades y métodos para indicar esos "mapeados".
Además, JPA simplifica aún más el trabajo gracias al uso de una serie de convenciones por defecto que sirven para un alto número de casos de uso habituales. Por ello, solo deberemos anotar aquellos comportamientos que queramos modificar o aquellos que no se pueden deducir de las propias clases. Por ejemplo, aunque existe una anotación (@Table) para indicar el nombre de la tabla en la base de datos que está asociada a una clase, por defecto si no indicamos otra cosa se considerará que ambos nombres coinciden. Por ejemplo, en el fragmento anterior, al haber anotado con @Entity la clase Factura se considera automáticamente que la tabla en la base de datos donde se guardan los datos de las facturas se llama también Factura. Pero podríamos cambiarla poniéndole la anotación @Table(name="Invoices"), por ejemplo.
Nota: también define una manera de hacerlo al revés, es decir, partir de una base de datos y generar a partir de esta las entidades de la aplicación, pero no se recomienda su uso.
2.- Tipos de datos personalizados
Todos los tipos de datos fundamentales estándar están soportados por JPA. Pero, también es posible dar soporte a tipos de datos propios, personalizados, utilizando lo que se llaman convertidores, a través de la interfaz AttributeConverter y la anotación @Converter.
3.- JPQL y consultas nativas
JPA define también su propio lenguaje de consultas llamado JPQL. Es similar a SQL y se utiliza para lanzar consultas específicas pero basadas en las entidades que tenemos en la aplicación y no en las tablas de la base de datos. Es decir, las consultas JPQL hacen referencia a las clases Java y sus campos en lugar de a tablas y columnas. Y además son independientes del motor de bases de datos.
A partir de estas consultas obtenemos ya directamente entidades de nuestra aplicación. Por ejemplo:
TypedQuery<Factura> consulta = modelo
.createQuery("SELECT f FROM Factura f WHERE f.id = :id", Factura.class);
consulta.setParameter("id", 5);
Factura f = consulta.getSingleResult();
También podemos lanzar consultas nativas a la base de datos:
Query consulta = modelo
.createNativeQuery("SELECT * FROM Factura WHERE id = :id", Factura.class);
consulta.setParameter("id", 5);
Factura f = (Factura) consulta.getSingleResult();
Las consultas JPQL son más limitadas que las que ofrece el lenguaje SQL, especialmente si consideramos las particularidades de los "dialectos" de cada motor de datos, pero son suficientes para un porcentaje alto de los casos. En cualquier caso, no deberíamos abusar de ninguno de los dos tipos de consultas, pues van en contra de la filosofía de los ORMs.
4.- Otras características
Aparte de todo lo mencionado, a lo largo de los años y las versiones JPA han ido añadiendo soporte para más funcionalidades como:
- Soporte de colecciones y listas ordenadas
- API Criteria para construcción de consultas
- API adicional para generación de consultas DDL (creación y modificación de estructura de la base de datos)
- Soporte para validaciones
- Ejecución de procedimientos almacenados
- Etc...
Como es habitual en las especificaciones del programa de proceso de comunidad de Java, el PDF de la especificación de JPA es bastante claro y legible, por si te interesa profundizar en el tema, te dejo el enlace a su última versión.
Implementaciones de JPA
Como llevo diciendo desde el principio, JPA es una especificación, así que para usarlo en la práctica necesitamos una implementación concreta, que implemente todas las interfaces y cuestiones definidas por la especificación.
La principal ventaja de esto es que, si las bibliotecas de persistencia que utilices siguen la especificación JPA, podrás cambiar de una a otra, con más rendimiento o características mejores, sin tener que tocar tu código, simplemente cambiando las referencias.
Existen diversas implementaciones disponibles, como DataNucleus, ObjectDB, o Apache OpenJPA, pero las dos más utilizadas son EclipseLink y sobre todo Hibernate.
La implementación de referencia de JPA, es decir, la implementación que proporciona la propia Fundación Eclipse y que sirve para ver cómo crear un ORM basado en la especificación, es EclipseLink. Esta implementación incluye soporte para persistencia en bases de datos relacionales, bases de datos documentales (como MongoDB), almacenes XML (especificación JAXB) y servicios web de bases de datos, por lo que es muy completa. Además añade otras características propias por encima de JPA, como son eventos para reaccionar a cambios en bases de datos o poder mapear entidades en diferentes bases de datos mismo tiempo.
La otra gran implementación de JPA es Hibernate, que en la actualidad es casi el "estándar" de facto, puesto que es la más utilizada, sobre todo en las empresas. Es tan popular que existen hasta versiones para otras plataformas, como NHibernate para la plataforma .NET. Es un proyecto muy maduro (de hecho, la especificación JPA original partió de él), muy bien documentado y que tiene un gran rendimiento.
¿Y qué pasa con Spring JPA?
Spring incluye también soporte para JPA, pero no es una implementación propia de JPA. Necesita una implementación como Hibernate o EclipseLink por debajo para funcionar.
Spring JPA ofrece una abstracción sobre JPA para facilitar la creación del patrón repositorio, muy útil para crear aplicaciones basadas en microservicios. Puede generar consultas JPA a través de convenciones de nombres. Y, además, tiene otra ventaja fundamental, y es que permite controlar los límites de las transacciones de manera declarativa utilizando la anotación @Transactional.
Así que Spring JPA no compite con Hibernate o con otras implementaciones, sino que las complementa, pudiendo utilizar Spring JPA con cualquiera de ellas y cambiar de unas otras si lo necesitas.
Spring también incluye Spring JDBC que es una capa de acceso a datos basada en el más sencillo JDBC y útil para hacer consultas nativas a bases de datos. No tiene nada que ver con JPA y puede ser muy útil y ágil para persistencia sencilla de información, evitando gracias a Spring toda la parafernalia propia del JDBC nativo.
En resumen
Cuando uno comienza a trabajar con Java puede resultar confusa tanta terminología, por lo que en este artículo he querido dar una visión general de qué es JPA, para qué sirve y cómo lo hace, cuáles son sus beneficios... y reseñar brevemente sus principales implementaciones.
Otra confusión común se da entre los distintos frameworks de acceso a datos, como Hibernate o EclipseLink y frameworks más amplios que también incluyen soluciones para acceso a datos, como Spring.
Espero que haya quedada clara la diferencia entre todos ellos.
Fecha de publicación: