
Vamos a ver con un ejemplo de qué modo podemos solucionar una situación común que se da en bases de datos.
Imaginemos que tenemos dos tablas relacionadas entre sí. La primera contiene datos de productos (su nombre, descripción, precio, etc...). La segunda es una tabla de categorías a las que pueden pertenecer los productos. Como un producto puede estar en más de una categoría a la vez, existe una tercera tabla que relaciona a las dos anteriores.
El ejemplo, por supuesto, podría ser con cualquier otro tipo de tablas y datos, pero con este tan sencillo ilustraremos bien nuestro caso.
Para visualizarlo mejor vamos a pintar una representación sencilla de estas tres tablas y sus relaciones:
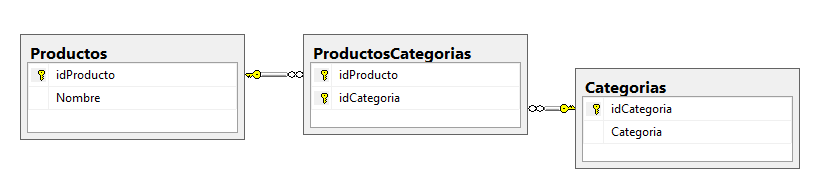
Y estos son algunos datos de prueba en ellas:
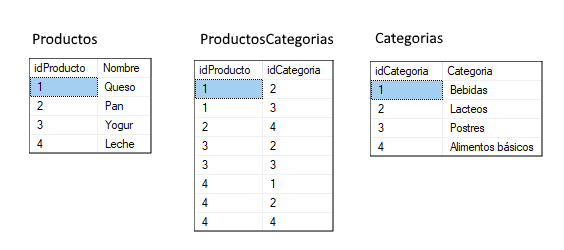
Como vemos, algunos productos están en más de una categoría. Por ejemplo, el yogur está en lácteos y postres, y la leche está en esos dos y además en bebidas.
Podemos obtener un listado con todos los productos y sus categorías usando una consulta de tipo INNER JOIN entre ambas tablas, por ejemplo esta:
SELECT Productos.Nombre, Categorias.Categoria
FROM Categorias INNER JOIN
ProductosCategorias ON Categorias.idCategoria = ProductosCategorias.idCategoria INNER JOIN
Productos ON ProductosCategorias.idProducto = Productos.idProducto
Lo cual nos devuelve el siguiente listado:
| Nombre |
Categoria |
| Queso |
Lacteos |
| Queso |
Postres |
| Pan |
Alimentos básicos |
| Yogur |
Lacteos |
| Yogur |
Postres |
| Leche |
Bebidas |
| Leche |
Lacteos |
| Leche |
Alimentos básicos |
Donde vemos cada producto y sus categorías.
El problema de esta consulta es que es un producto cartesiano, por lo tanto nos devuelve un registro por cada categoría del producto, es decir, si un producto está en tres categorías tenemos tres registros para el mismo producto como resultado de la consulta (mira por ejemplo la leche al final).
Por supuesto podríamos efectuar una agrupación y contar a cuántas categorías pertenece cada producto, pero si queremos ver cuáles son específicamente, entonces necesitamos tener varias veces el mismo producto en los resultados.
Pero ¿qué pasa si necesitamos tener en un solo campo todas las categorías de cada producto agrupadas y listas para usar?...
Es decir, algo como esto:
| Nombre |
Categorias |
| Queso |
Lacteos, Postres |
| Pan |
Alimentos básicos |
| Yogur |
Lacteos, Postres |
| Leche |
Bebidas, Lacteos, Alimentos básicos |
Donde solo tenemos una fila por cada producto, y un nuevo campo ficticio llamado Categorias que contiene todas las categorías separadas por una simple coma.
Vamos a ver cómo conseguirlo paso a paso...
1.- Subconsulta para obtener las categorías
Lo primero que vamos a ver es cómo podemos obtener, para un producto dado, todas las categorías a las que este pertenece. En realidad ya sabemos hacerlo a partir de la consulta anterior, quedándonos solo con la parte de las tablas de categorías y la intermedia, y metiendo un filtro por el identificador del producto, así:
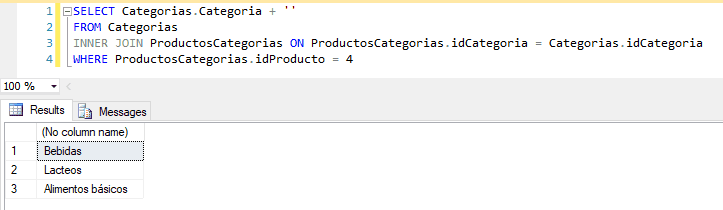
SELECT Categorias.Categoria
FROM Categorias
INNER JOIN ProductosCategorias ON ProductosCategorias.idCategoria = Categorias.idCategoria
WHERE ProductosCategorias.idProducto = 4
En este caso obtenemos todas las categorías del producto 4, o sea, la leche. Nos devuelve tres líneas de resultados, una por cada categoría.
Pero ¿cómo podemos hacer para que en lugar de 3 líneas como ahora, nos devuelva todas las categorías concatenadas en una sola cadena de texto?
2.- La conversión a XML que nunca lo fue
Desde SQL Server 2005 existe una característica integrada en su lenguaje de consultas T-SQL que sirve para obtener resultados en formato XML. Se trata de la cláusula FOR XML.
Ésta permite obtener un único campo como respuesta de una consulta que contiene una representación en XML de los datos devueltos por ésta. Por ejemplo, si a la consulta anterior le añadimos un FOR XML AUTO, así:
SELECT Categorias.Categoria
FROM Categorias
INNER JOIN ProductosCategorias ON ProductosCategorias.idCategoria = Categorias.idCategoria
WHERE ProductosCategorias.idProducto = 4
FOR XML AUTO
Obtendremos este resultado:
<Categorias Categoria="Bebidas"/>
<Categorias Categoria="Lacteos"/>
<Categorias Categoria="Alimentos básicos"/>
Como vemos devuelve los registros con el nombre de la tabla como nodo XML y un atributo con el nombre del campo para el resultado.
Esta cláusula tiene diversas variantes que cambian la forma del XML devuelto. Una de ellas, la que nos interesa, es FOR XML PATH que permite especificar qué elemento queremos usar para rodear a los resultados anteriores. Es decir, el nodo raíz. Además, tiene otra particularidad: si un campo que devolvamos no tiene nombre, lo devuelve tal cual, como un valor dentro del XML, ya que no tiene forma de ponerle un atributo o un nodo para rodearlo (FOR XML AUTO no permite campos sin nombre en el resultado).
¿Cómo conseguimos un campo sin nombre? Pues simplemente cualquier campo calculado al que no le asignemos uno con AS, será sin nombre. Así, basta por ejemplo con concatenar una cadena vacía a un campo para que deje de tener nombre:
Bien. Entonces, teniendo en cuenta estas dos cosas, ¿cómo conseguimos concatenar el valor del campo, por ejemplo, separándolo con comas?
Pues usando un campo sin nombre y no rodeando al XML con nodo alguno, así:
SELECT ', ' + Categorias.Categoria
FROM Categorias
INNER JOIN ProductosCategorias ON ProductosCategorias.idCategoria = Categorias.idCategoria
WHERE ProductosCategorias.idProducto = 4
FOR XML PATH ('')
Que nos devuelve un resultado XML que en realidad no es XML ya que obtenemos:
, Bebidas, Lacteos, Alimentos básicos
Como vemos esto es casi lo que queríamos: le sobra la coma inicial.
3.- Librarnos de la coma inicial
Vale. Ya tenemos casi lo que necesitamos, pero nos sobra esa coma del principio. Por suerte es muy fácil librarse de ella gracias a una función específica de T-SQL denominada STUFF.
Esta función inserta una cadena dentro de otra. Elimina una longitud determinada de caracteres de la primera cadena a partir de la posición de inicio y, a continuación, inserta la segunda cadena en la primera, en la posición de inicio.
Es decir, en una cadena, a partir de la posición que le digamos, elimina los caracteres que le indiquemos y luego mete en ese lugar la cadena que queramos. Es como quitar e insertar por el medio, o sea, rellenar (que es el significado de la palabra stuff en inglés).
Por ejemplo, esta expresión:
SELECT STUFF('Pericardio', 5, 5, 'pl')
lo que hace es ir a la posición 5 (la "c" de "cardio"), eliminar 5 caracteres (o sea, "cardi"), y luego meter entre esa posición y lo que reste la cadena "pl". Con ello el resultado que obtenemos es la palabra:
Periplo
que aprovecha la "o" final.
En el caso que nos ocupa, por tanto, eliminar la coma y el espacio en blanco inicial es muy sencillo: se eliminan los dos primeros caracteres y se "inserta" una cadena vacía, así:
STUFF(Cadena, 1, 2, '')
Que si lo llevamos a la consulta anterior que devolvía las categorías en una cadena, es:
SELECT STUFF(
(SELECT ', ' + Categorias.Categoria
FROM Categorias
INNER JOIN ProductosCategorias ON ProductosCategorias.idCategoria = Categorias.idCategoria
WHERE ProductosCategorias.idProducto = 4
FOR XML PATH ('')),
1,2, '')
Obteniendo:
Bebidas, Lacteos, Alimentos básicos
Ya sin esa coma y espacio en blanco iniciales.
4.- Ahora todo junto
Ahora que ya sabemos cómo obtener los datos concatenados en una cadena solo resta mezclar eso con la consulta original, en la que queríamos obtener las categorías de cada producto. Esto es muy fácil de conseguir ahora simplemente metiendo la consulta que acabamos de crear como sub-consulta de la principal y asignándole un nombre. La cosa quedaría así:
SELECT Productos.Nombre,
STUFF(
(SELECT ', ' + Categorias.Categoria
FROM Categorias
INNER JOIN ProductosCategorias ON ProductosCategorias.idCategoria = Categorias.idCategoria
WHERE ProductosCategorias.idProducto = Productos.idProducto
FOR XML PATH('')),
1, 2, '') As Categorias
FROM Productos
Como vemos, es una simple consulta que devuelve dos campos, siendo el segundo de ellos una sub-consulta que genera la lista de categorías de cada producto a partir de su identificador (ahora en el WHERE en lugar de poner un valor constante usamos el valor del campo idProducto de la consulta principal).
Con esto conseguimos exactamente lo que necesitábamos y veremos este resultado:
| Nombre |
Categorias |
| Queso |
Lacteos, Postres |
| Pan |
Alimentos básicos |
| Yogur |
Lacteos, Postres |
| Leche |
Bebidas, Lacteos, Alimentos básicos |
¡Listo!
En conclusión
Esta técnica tiene multitud de aplicaciones prácticas, que van más allá del ejemplo que acabamos de hacer.
En el rendimiento no tiene demasiado impacto, salvo quizá si concatenamos enormes cantidades de datos para obtener una gran cadena.
Si observamos el plan de ejecución de la primera consulta que hace el producto cartesiano:
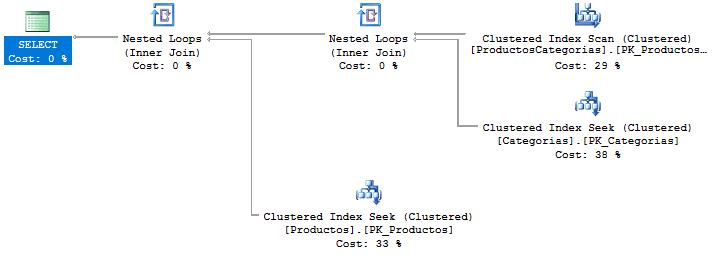
Y el plan de ejecución de la consulta final:
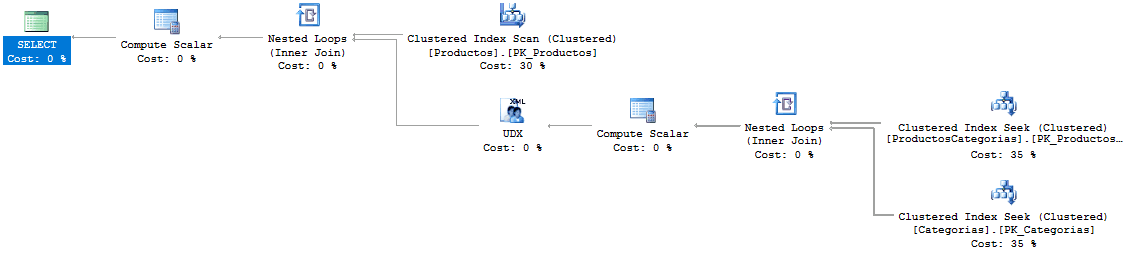
Vemos que son muy parecidos, y además se sabe que la concatenación con FOR XML PATH tiene un impacto muy pequeño pues está muy optimizada por el motor de datos.
Una cosa importante a tener en cuenta: si el contenido de los textos que concatenamos tiene caracteres propios de etiquetas HTML o XML, básicamente símbolos de menor y mayor (< o >) y el "et" o "ampersand" (&), éstos se devolverán codificados como HTML, es decir, como <, > y &. El motivo es que lo que se está devolviendo es XML (aunque no lo parezca) y los datos deben ir correctamente codificados. Esto de hecho puede ser muy útil si estamos en una aplicación web, ya que no tendremos ni que codificarlos para mostrarlos. Pero si puede suponer un problema debemos tenerlo en cuenta en la aplicación que haga uso de los datos devueltos y volver a codificarlos con los caracteres iniciales.
Actualización 29/Dic/2017: Un par de cosas más, sugeridas por Pablo Doval (¡Gracias Pablo!):
- Es mejor no utilizar esta técnica dentro de una función definida por el usuario (UDF) pues provoca una dramática pérdida de rendimiento en ese caso.
- Si utilizas SQL Server 2017 o posterior, ahora hay soporte nativo del lenguaje T-SQL para hacer lo mismo a través de la función STRING_AGG, que es de uso directo para conseguir lo mismo.
Si lo deseas te puedes bajar (ZIP, 3KB) la pequeña base de datos de ejemplo que he utilizado para este artículo, junto con un archivo con las diferentes consultas utilizadas de modo que puedas probarlo con más facilidad.
¡Espero que te resulte útil!
Fecha de publicación: